Decentralized Curation: Trustless Transformation of Information into Knowledge
1 Abstract
The internet solved access to information but not access to knowledge. The unresolved bottleneck is curation: the transformation of raw information into decision-grade knowledge. This bottleneck is upstream of many failures usually described as failures of governance, media, or coordination. The problem is becoming structurally worse because generative AI makes the form of quality cheap while leaving the substance of quality expensive. We can now generate fluent prose, plausible structure, and respectable presentation far more cheaply than we can generate correctness, coherence, or grounded judgment.
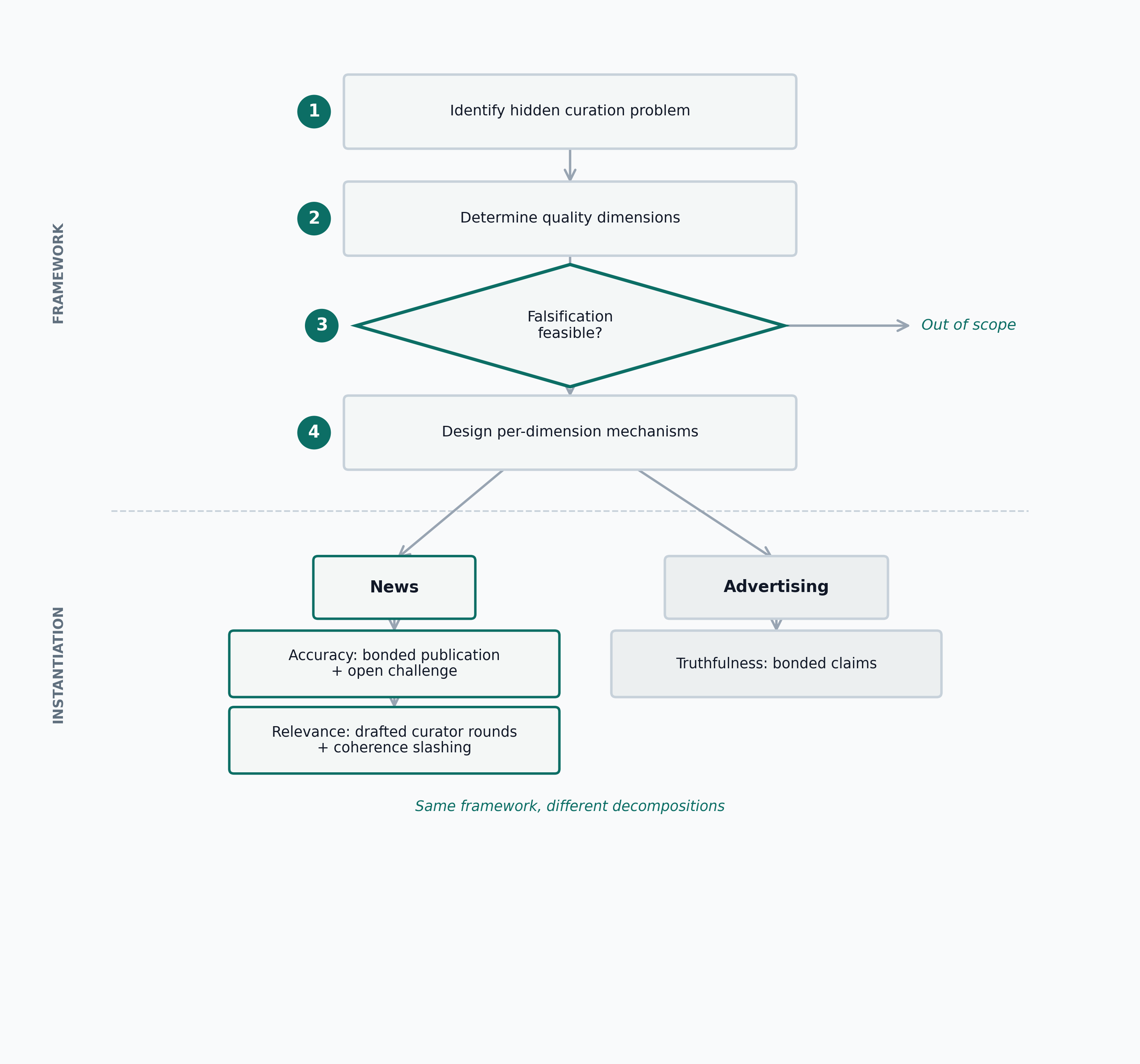
This paper proposes, as a working hypothesis, that many information-heavy coordination problems decompose into a curate-then-coordinate structure and that the difficulty is concentrated in the curation phase rather than the coordination phase. It develops a general framework for trustless decentralized curation and examines the hypothesis on one domain (news) with full mechanism design, simulation, and partial deployment. The framework has four steps: identify the hidden curation problem behind an apparent downstream failure; identify the relevant quality dimensions; require falsifiability where the mechanism depends on challenge; and design distinct mechanisms for each quality dimension instead of collapsing all quality into one score. We instantiate the framework for news, where two dimensions dominate: accuracy, which is global and binary, and relevance, which is local and scalar.
The protocol design reflects that decomposition. Accuracy is handled through bonded publication, open challenges, and external decentralized dispute resolution. Relevance is handled through drafted curator rounds under a public policy, with coherence-based rewards and slashing. Confidence is accumulated bond-time rather than a truth label. Author reputation acts as a slow-moving non-monetary bond. Pool creation is permissionless, contracts are treated as immutable, and governance is minimized by design: we prefer no need for governance over good governance.
Truth Post, launched in 2023, implemented the accuracy layer only. Public on-chain activity remained sparse, which is enough to classify the deployment as an unsuccessful bootstrap but not enough to identify a single cause. The deployment still showed that a live bonded-publication system could be launched on-chain, and the experience motivated the redesign presented here. Redesigned simulations in this paper show that debunking false claims is economically attractive under reasonable juror accuracy, that drafted-curator relevance rounds filter competence while remaining vulnerable above a concrete collusion threshold, and that author reputation as a standing bond creates useful separation between honest and dishonest publishers without reintroducing reputation-weighted voting.
This paper addresses only the information-to-knowledge transformation. Coordination given trusted shared knowledge is out of scope.
2 Introduction
When you search for travel destinations, you are consuming someone else’s curation. When you read a newspaper, you are consuming someone else’s curation. When you rely on rankings, reviews, feeds, summaries, or recommendations, you are outsourcing judgment. That is useful. No individual can verify, sort, and evaluate the whole world manually. But the moment you depend on a curator, you inherit that curator’s competence, incentives, and failure modes.
This dependency matters because information is not knowledge. Raw information becomes useful only after it has been selected, verified, and contextualized. That transformation is curation. The internet radically improved access to information; it did not solve access to knowledge.
This paper proposes a working hypothesis: many information-heavy coordination problems decompose into curate-then-coordinate, and the difficulty is concentrated in the curation phase, not the coordination phase. The hypothesis is examined on one domain (news) with full mechanism design, simulation, and partial deployment; other domains are discussed as plausible extensions, not proven applications.
Take news. A newspaper is a curated set of claims about reality. People consume those claims and then make decisions. In a democracy, those decisions are collective and consequential. If the curation layer is incompetent, voters act on low-quality knowledge. If the curation layer is weaponized, voters act on poisoned knowledge (Chomsky and Herman 1988). In both cases the downstream damage is the same: people coordinate on corrupted inputs.
This is why I propose that many coordination failures are misdiagnosed. We keep trying to fix governance, voting, or collective decision-making directly while standing on a broken knowledge layer. People cannot coordinate well without a trusted shared reality. If two people trust that two plus two equals four, there is no coordination problem there; the shared fact scales. But when two groups inhabit different constructed realities about politics, institutions, or public events, governance becomes hard, on this account, not because humans are incapable of coordination, but because the knowledge layer underneath coordination is degraded.
So governance is often a hidden curation problem.
This paper addresses that upstream layer only. It is about the transformation from information into decision-grade knowledge, not about coordination after knowledge has been established. That distinction matters. The downstream coordination literature is rich. My claim is that many deployments fail before that stage because the curation layer is missing, captured, or opaque.
2.1 Information abundance, knowledge scarcity
The internet gave everyone access to unprecedented volumes of information. It did not give everyone access to reliable knowledge. The distinction is structural. A pile of unsorted books and a library can contain the same pages; what differs is the mechanism that organizes, filters, and makes them usable.
The progression from data through information to knowledge is a well-established concept in information science, formalized in Ackoff’s DIKW hierarchy (Ackoff 1989). The hierarchy names the levels but does not specify how the transformation between them is performed or verified. Subsequent critiques have noted exactly this gap: the framework is descriptive, not prescriptive. This paper proposes concrete mechanisms for one transition in that hierarchy: from information to decision-grade knowledge, through selection, verification, and contextualization.
Historically, some of that mechanism was carried by institutions: newspapers, journals, universities, editors, teachers, peer reviewers. Those institutions were imperfect, but they were legible enough that users could at least understand where the curation happened. Today we have more information than ever and weaker, more opaque transformations from information into knowledge.
Generative AI makes the gap wider. Producing functional software required understanding it; writing a convincing paper required the competence it demonstrated. That requirement functioned as an implicit proof of work: the cost of producing the artifact was inseparable from the knowledge it signaled. AI weakens this coupling by making production possible without understanding. The form of quality is now cheap: formatting, fluency, plausible citation patterns, respectable structure. The substance of quality remains expensive: correctness, coherence, domain understanding, and judgment. We are entering a regime of information abundance and knowledge scarcity.
That is why curation is not a side problem. Under the hypothesis of this paper, it is becoming a central bottleneck in collective decision-making.
2.2 Contributions
This paper contributes:
- A general framework for trustless decentralized curation. The framework is a method for identifying when decentralized curation is feasible and how to decompose the mechanism. This paper fully instantiates it for news (with mechanism design, simulation, and partial deployment) and sketches a second application to advertising; broader generality is a design goal, not a demonstrated property.
- A complete end-state protocol architecture for Truth Post. The design separates accuracy from relevance, distinguishes on-chain canonical state from replaceable interfaces, makes pool creation permissionless, and treats contracts as immutable with cross-version coexistence rather than in-place upgrades.
- A simulation-based evaluation program. The experiments test the economic viability of challenge-based accuracy verification, the filtering power and collusion resistance of drafted-curator relevance rounds, and the separating effect of author reputation as a standing bond.
- A deployment retrospective. Truth Post (2023) produced a live partial deployment of the accuracy layer and revealed the bootstrapping conditions the current design must satisfy.
3 A General Framework For Trustless Decentralized Curation
The central contribution of this paper is a general four-step framework (Figure 1):
- Problem definition. Identify the hidden curation problem inside what is usually described as a downstream failure.
- Quality identification. Determine which dimensions of information quality actually matter in the target domain.
- Falsifiability requirement. Use challenge-based mechanisms only where falsification is feasible and cheaper than exhaustive verification.
- Mechanism design by dimension. Design different mechanisms for different quality dimensions instead of forcing all quality into one signal.
The framework is designed to be domain-agnostic: the four steps are not specific to any single domain, and what changes across domains is the quality decomposition and the mechanism mix. This paper fully instantiates one domain (news) and sketches a second (advertising). The architectural pattern is intended to generalize, but demonstrated generality requires additional instantiations beyond those presented here.
3.2 Step 2: identify the relevant quality dimensions
Information quality is not one thing. Wang and Strong’s data-quality work is useful here because it treats quality as multidimensional rather than monolithic (Wang and Strong 1996). Different domains care about different dimensions: accuracy, relevance, timeliness, interpretability, completeness, accessibility, and so on.
The practical consequence is simple: there is no universal curation mechanism. If a system tries to compress all quality into one score, it usually confuses properties that need different incentives.
3.3 Step 3: require falsifiability
Popper’s core point remains operationally useful: a claim is meaningful for scientific inquiry when it exposes itself to potential refutation (Popper 1959). The same asymmetry matters here. If a claim is trivially verifiable, a curation mechanism is unnecessary. If a claim is not falsifiable at all, a challenge mechanism has nothing to latch onto.
The relevant region is the middle one (Figure 2):
- verification is difficult or expensive
- falsification is feasible
- the evidence needed to falsify is publicly accessible
News fits this structure well. A claim that an event happened can be expensive to verify exhaustively, but later evidence can still debunk it. The mechanism therefore does not need to prove all truth from scratch. It needs to make falsehood attackable.

3.4 Step 4: design mechanisms dimension by dimension
Different dimensions need different mechanisms. In the news domain, accuracy and relevance are not the same problem. Accuracy is global and binary: a claim either withstands a debunking challenge or it does not. Relevance is local and scalar: what matters depends on the pool’s public policy, scope, and current context.
Trying to solve both with one mechanism is a category error.
3.5 A second instantiation: advertising
Advertising shows that the framework is not confined to journalism. Advertising is largely a competition for attention in which participants keep spending until the game reaches its feasibility limit. In that sense it resembles other negative-sum escalation games: arms races, extractive competition, or resource-burning contests.
A different advertising game is possible. Instead of paying for distribution regardless of truth, advertisers can express ads as claims and post a bond behind them. If the claim is true, the cost is mainly temporary capital lockup. If the claim is false, the capital is lost to challengers. This inverts the current cost structure: honest advertisers are cheap to accommodate, dishonest advertisers become expensive.
Advertising therefore serves two purposes in this paper. It illustrates that the framework’s four steps can be applied outside journalism, though this sketch does not constitute a full instantiation (no quality decomposition, simulation, or deployment has been performed for advertising). It also provides a plausible funding source for curation labor even when political or journalistic disputes are quiet (Juniper Research 2023).
4 Instantiating The Framework For News
News is the first serious instantiation because the curation problem is socially visible, broadly distributed, and politically consequential.
4.1 Accuracy and relevance
Applying the framework to news yields two dominant quality dimensions:
- Accuracy. Claims should withstand public challenge under an explicit evidence standard.
- Relevance. Claims should matter relative to the pool’s curation goal.
Accuracy alone is not sufficient. A claim like “one equals one” is accurate, but it is not news. A world-politics pool that publishes accurate football trivia has not solved its curation problem. Relevance is therefore not an optional add-on. It is a separate dimension with different structure and different incentives.
4.2 Falsifiability and claim structure
The protocol cannot operate on vibes. It needs claims that expose themselves to challenge. In the complete design, the unit is a claim blob: a content-addressed article or item that may contain multiple propositions. A challenger does not need to attack the entire blob at once; they identify an explicit challenged proposition in natural language. If that challenge succeeds, the entire item is debunked.
This design intentionally avoids pretending that the protocol determines truth in an absolute sense. The complete design tracks claims along two separate state dimensions. The operational state records the claim’s lifecycle position:
Live: the item is active, bonded, and challengeable. Confidence accrues.PendingEdit: the author is preparing a new revision. Confidence is paused. The claim remains challengeable on its last finalized revision.WithdrawPending: the author has initiated withdrawal. A cooldown period runs during which challenges are still accepted.Challenged: an active dispute is in progress. Confidence is paused.Closed: a challenge succeeded; the claim is terminal for feed purposes.Withdrawn: the author removed the bond after the cooldown; the item remains visible historically with frozen confidence.
The adjudication outcome records the result of accuracy disputes separately:
Unchallenged: no challenge has been resolved.ChallengeFailed: a challenge was resolved in the author’s favor.Debunked: a challenge succeeded, whether by counter-evidence, because the challenged proposition was non-falsifiable, because the claim violated the pool’s topic scope, or because the claim failed the pool’s template requirements.
The important point is institutional modesty. Truth Post is not an oracle of metaphysical truth. It is a system for transparency, contestability, and incentives.
5 Complete Truth Post Design
This section treats the current Truth Post blueprint as the canonical design. The 2023 deployment is not the design source of truth; it is a partial historical predecessor.
5.1 Architectural stance
Three architectural commitments anchor the design:
- Permissionless pools. Any address may create a pool with a domain, a claim template, an evidence policy, and a relevance policy. If the pool is bad, interfaces and users can ignore it.
- Immutable contracts. Protocol changes require new deployments and cross-version aggregation, not in-place upgrades.
- Minimal governance. The preference ordering is: eliminating the need for governance is best; good governance is acceptable; bad governance is worse; and no governance at all (ungoverned failure modes) is worst. If a design can eliminate a governance surface, it should.
These commitments are not aesthetic. They reduce capture surface area. The closer a protocol gets to “someone must govern this correctly forever,” the closer it gets to rebuilding the same trust problem at a different layer.
The departure from Ostrom’s commons governance framework is deliberate (Ostrom 1990). Ostrom’s design principles were derived from small-to-medium communities with persistent identity, bounded exit options, and repeated face-to-face interaction. Digital curation pools partially replicate some of these conditions: staked capital creates persistent pseudonymous identity, accumulated reputation creates exit costs, and repeated curator drafting into the same pool constitutes a repeated game. However, the degree of replication is weaker than in Ostrom’s canonical cases. Creating a new pseudonymous identity is cheap (one Ethereum address), exit costs from reputation are pool-scoped and decay over time, and interaction is mediated by code rather than the social norms that sustain compliance in face-to-face commons. In this environment, governance surfaces are more capturable (because identity proliferation is easy and coordinating a voting bloc requires only a shared key or multisig) and exit is more attractive than voice (because switching pools is cheaper than reforming a captured one). The preference ordering follows from this asymmetry: when governance is easier to capture than to defend, eliminating governance surfaces dominates designing elaborate governance.
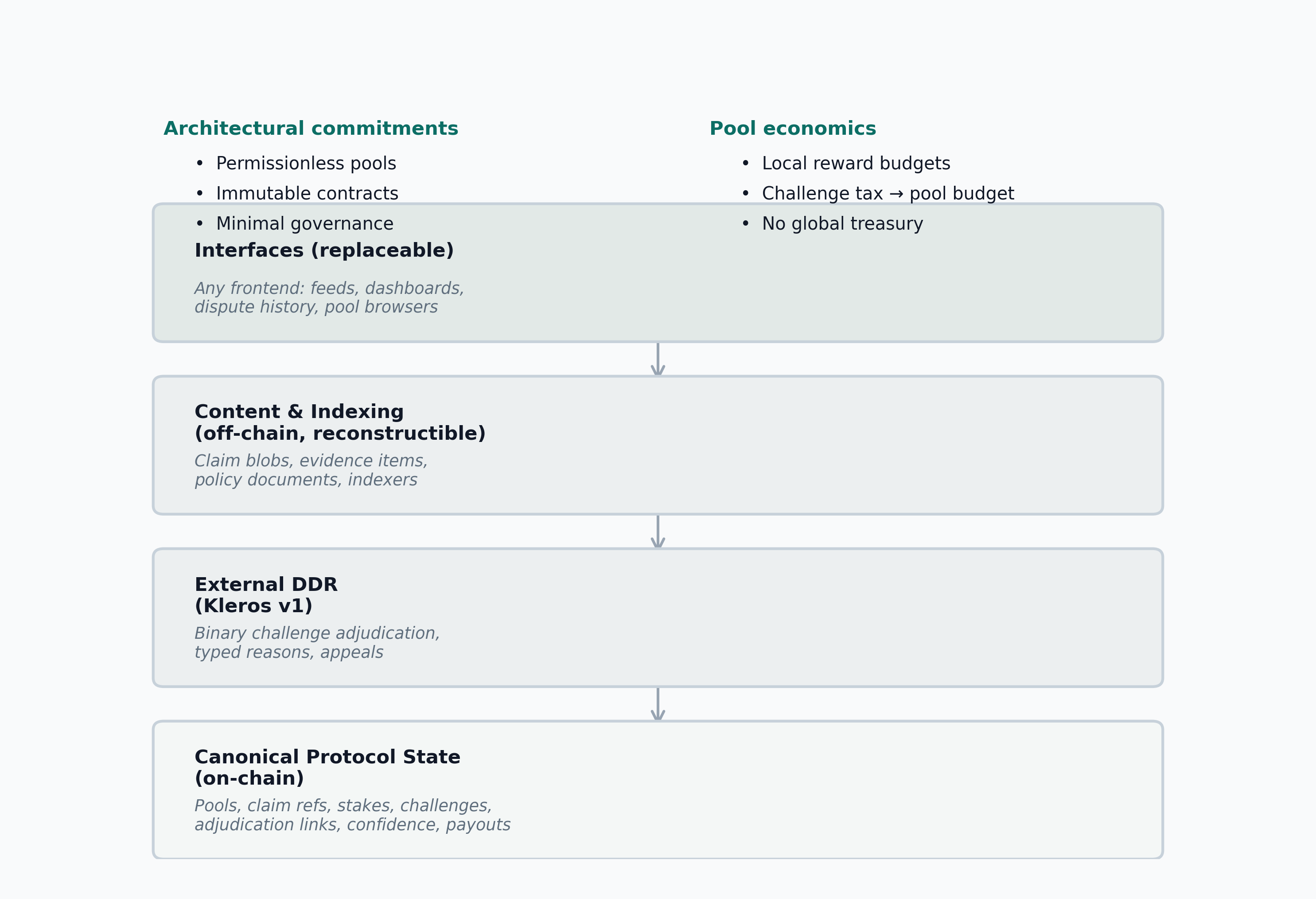
5.2 Canonical system boundary
Truth Post is not a single website. The protocol has four layers (Figure 3):
- Canonical protocol state: pools, claim references, stakes, challenge state, adjudication links, confidence accounting, and payout logic.
- External DDR: binary challenge adjudication with typed challenge reasons and appeals, delegated to an external decentralized dispute resolution provider.
- Content and indexing: claim blobs, evidence items, policy documents, and indexers that reconstruct feeds and histories from canonical state.
- Interfaces: any frontend or application that renders feeds, article pages, pool dashboards, or dispute history.
This split is part of the design, not an implementation detail. A protocol with one fragile frontend is not practically decentralized. The same claim blob CID may be posted to multiple pools as independent claims; each pool instance has independent adjudication, confidence, and relevance.
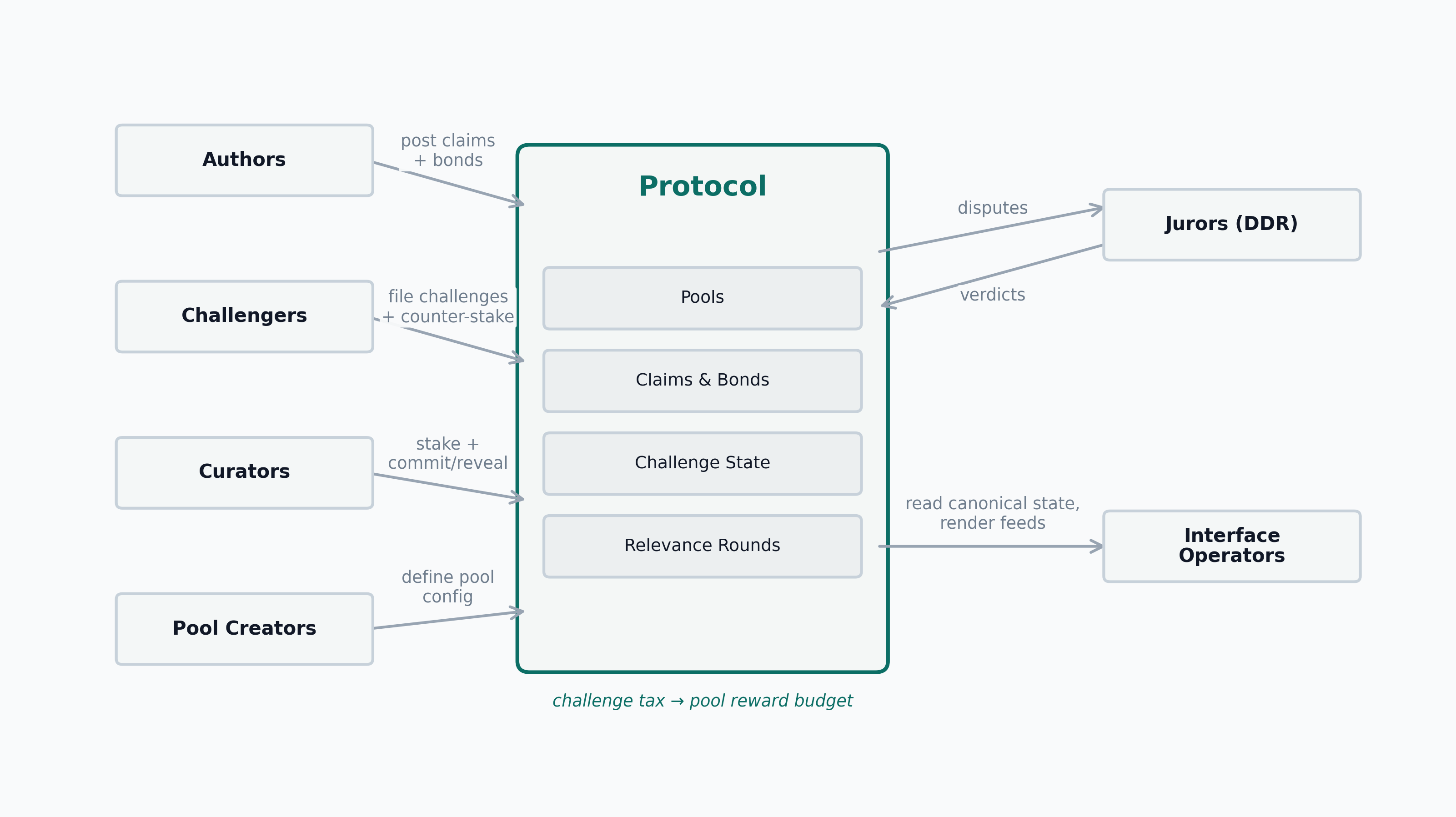
5.3 Actors
- Authors submit claim blobs, post author bonds, and may later withdraw or amend claims.
- Challengers file counter-stake, counter-evidence, and an explicit challenge reason against a challenged proposition.
- Curators stake into pools and become eligible for drafted relevance rounds.
- Jurors belong to the external decentralized dispute resolution layer and adjudicate only accuracy disputes.
- Pool creators define one pool configuration. They do not govern the protocol as a whole.
- Interface operators decide what to surface, feature, warn about, or ignore.
- Readers consume the outputs and may later become authors, challengers, or curators.
5.4 Accuracy layer
The accuracy mechanism is a bonded publication and challenge system (Figure 5).
- An author posts a claim blob and locks a bond. Contracts enforce minimal structural field presence at submission (non-empty CIDs, valid version pointers).
- The item enters
Livestatus immediately and remains challengeable while bonded. Authors may adjust their bond while live, subject to a pool-scoped grace period; the old bond rate continues for confidence accrual and challenge pricing until the adjustment takes effect. - A challenger may file one active challenge at a time against a specific proposition inside the item, with queued challenges allowed behind it. Challenges may also be filed against claims in
PendingEditorWithdrawPendingstates, targeting the last finalized revision. - The challenger pays a counter-stake (
max(pool minimum, bond/4)), a challenge tax (a pool-configurable percentage of the pinned bond), and the external DDR fee. Each challenge is pinned to the challenged revision, manifest CID, and bond at filing time, so later edits or bond changes do not alter the dispute target or payout basis. For queued challenges, the counter-stake, tax, and DDR fee remain in escrow until activation; tax is credited to the pool budget only on activation. - The dispute goes to external DDR with a binary question: should the challenge succeed? Appeals, if any, are handled entirely by the external DDR. The protocol does not implement its own escalating-stakes appeal ladder or any protocol-native “lone expert versus herd” jackpot.
- If the challenge succeeds, the item moves to
Closedwith adjudication outcomeDebunked. The challenger receives the author’s bond and their own counter-stake back; the challenge tax remains in the pool budget. If the challenge fails, the item returns to its pre-challenge operational state. The author keeps the bond; the challenger’s counter-stake is split between author reward and pool reward budget at a pool-configurable ratio. The split ratio is a pool parameter, not a protocol constant: too much to the author weakens pool funding; too much to the pool weakens the author’s incentive to defend claims. The DDR fee is a sunk challenger cost in both outcomes.
The protocol supports four typed challenge reasons, none of which is a separate final verdict. All yield Debunked on success:
Debunking: the challenged proposition is factually false.NonFalsifiable: the challenged proposition fails to instantiate a falsifiable claim under the pool’s template and evidence policy.ScopeViolation: the claim does not belong in the pool’s declared topic domain.TemplateViolation: the claim passes on-chain structural checks but fails the pool’s semantic template requirements (e.g., missing required fields or disallowed source classes). On-chain structural validation is enforced at submission; semantic template conformance is enforceable post-publication through this challenge reason.
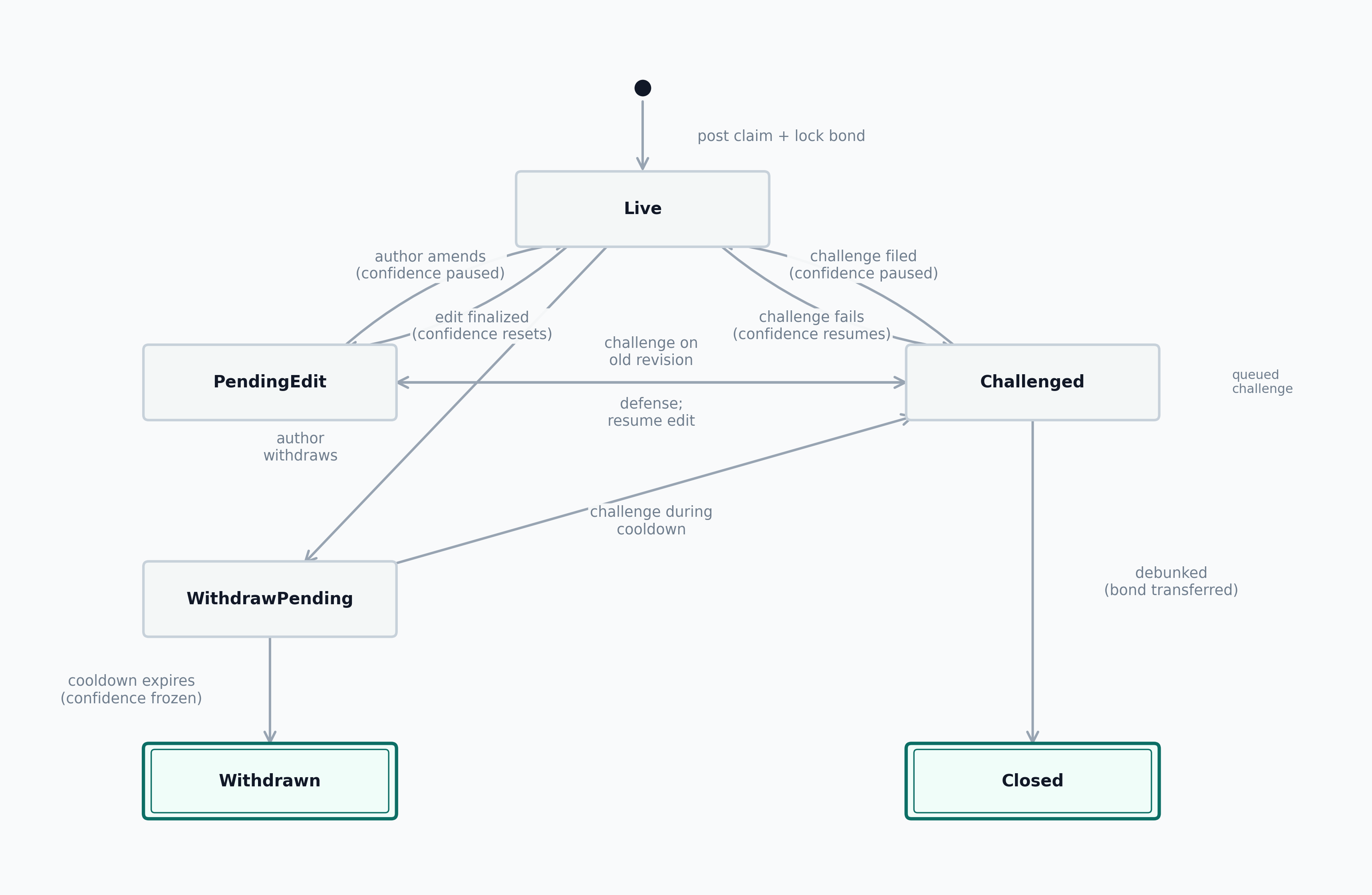
Live on bonded publication. Challenges route through external DDR; successful challenges lead to Closed/Debunked (bond transferred), failed challenges restore the pre-challenge state. Author-initiated withdrawal enters a cooldown (WithdrawPending) during which challenges are still accepted. Author-initiated amendment enters PendingEdit, where the claim remains challengeable on its last finalized revision. Terminal states have double borders.
5.5 Relevance layer
The relevance mechanism is a drafted curator coherence game (Figure 6).
- Curators deposit tokens into a pool contract. Let s_i denote curator i’s deposited balance, with both s_i and the seat size L measured in the token’s smallest on-chain unit. The deposited balance is the curator’s total capital in the pool; portions not locked in active rounds are withdrawable at any time.
- Relevance rounds are scheduled for
Liveitems at a pool-defined cadence. - Each seat in the lottery corresponds to L locked tokens (pool-configurable, L > 0). Only curators with s_i \ge L are eligible; the draft weight d_i is the integer number of full seat-tickets the curator holds, computed by rounding down:
d_i = \lfloor s_i / L \rfloor
- The protocol draws seats from the ticket pool. Each drawn ticket locks L tokens from the corresponding curator. A curator may receive at most d_i seats in a single round. Let n_i denote the number of seats drawn for curator i. The curator’s round weight w_i equals their total locked tokens:
w_i = n_i \cdot L
Locked tokens are simultaneously the curator’s influence on the weighted mean and their maximum loss. The unlocked remainder (s_i - n_i \cdot L) stays in the pool contract but is not at risk in this round and is withdrawable.
Each drafted curator commits and reveals a single relevance score in [0,1], weighted by w_i. Multiple seats increase the curator’s weight on that single score, not the number of independent votes.
The protocol computes the weighted mean \mu and weighted standard deviation \sigma of submitted scores. If no curators reveal (W = 0), the round is cancelled: no score is produced, the claim retains its previous relevance score if one exists, and all locked tokens are returned. Otherwise, let W = \sum_i w_i > 0 denote the total round weight:
\mu = \frac{1}{W}\sum_i w_i \, v_i, \qquad \sigma = \sqrt{\frac{\sum_i w_i (v_i - \mu)^2}{W}}.
Round rewards scale linearly with \sigma rather than switching at a threshold. Let \varepsilon_\sigma > 0 denote a pool-configurable dispersion floor, and define the reference dispersion level by
\sigma_{\mathrm{ref}} := \max\!\Bigl(\varepsilon_\sigma,\;\operatorname{median}(\sigma_{t-h},\ldots,\sigma_{t-1})\Bigr),
where the median is taken over a rolling window of recent rounds. This preserves adaptation without governance while guaranteeing \sigma_{\mathrm{ref}} > 0 even during sustained consensus. Let R denote the base round reward drawn from the pool’s local reward budget, and let \rho \in [0, 1] denote the minimum reward fraction for zero-dispersion rounds. The reward factor is:
f_{\mathrm{reward}} = \rho + (1 - \rho) \cdot \min\!\Bigl(1,\;\frac{\sigma}{\sigma_{\mathrm{ref}}}\Bigr)
At \sigma = 0, the reward is \rho R (minimum); at \sigma \ge \sigma_{\mathrm{ref}}, the reward is full R; between them the transition is linear. This avoids the cliff that a hard threshold would create: a step function that switched from reduced to full rewards at a fixed cutoff would incentivize curators to inject artificial variance (score 0.87 instead of 0.90) to cross the threshold, producing systematic bias. The smooth curve removes that discontinuity, but for \sigma < \sigma_{\mathrm{ref}} rewards still increase monotonically with \sigma. The protocol therefore does not rely on the reward curve alone to eliminate variance-padding incentives: lazy convergence and genuine consensus appear structurally indistinguishable under the observables available to the protocol at the single-round level, so the defense is the lifetime expected value. Low-\sigma rounds pay reduced rewards, and a visibly wrong lazy score can be appealed and overturned (slashing the lazy curators), making mechanically inflated dispersion unattractive over repeated participation. When \sigma is near zero, the coherence band collapses and the graduated slashing rule (step 7) is skipped at finalization (the slashing formula divides by \sigma); the mean is still accepted as a valid relevance score and the round-specific lock is released back into each curator’s deposited balance. That balance remains slashable for this round until the appeal window expires: withdrawals during the appeal window are allowed only to the extent that they do not reduce the deposited balance below the curator’s outstanding appeal exposure. If a subsequent appeal succeeds under step 8, the protocol debits the slash from that reserved balance; if no appeal is filed before the window closes, the reserve is removed and the balance becomes fully withdrawable.
- If \sigma \ge \varepsilon_\sigma (the same dispersion floor used in \sigma_{\mathrm{ref}}), graduated slashing applies. Let v_i denote curator i’s revealed score and let K denote the coherence-threshold multiplier (K > 0). Curators inside the coherence band (|v_i - \mu| \le K\sigma) are not penalized. Curators outside the band lose a fraction of their locked tokens that scales linearly with distance:
p_i = \min\!\Bigl(1,\;\max\!\bigl(0,\;\frac{|v_i - \mu|/\sigma - K}{K}\bigr)\Bigr)
At the band boundary, the penalty is zero; at twice the boundary distance (2K\sigma from the mean), the penalty is total loss of locked tokens. Since w_i is measured in smallest on-chain units (integers), the slashed amount is rounded down:
\delta_i = \lfloor p_i \cdot w_i \rfloor, \qquad q_i = w_i - \delta_i.
The protocol slashes \delta_i tokens and returns the remainder q_i. This graduated slashing replaces binary slashing: near-boundary deviations incur small losses, while extreme deviations incur total loss. If \sigma < \varepsilon_\sigma, step 7 is skipped entirely: p_i = 0 for all curators, \delta_i = 0, and all locked tokens are released from finalization.
- Any curator with a deposited balance in the pool may appeal a finalized relevance round by posting an appeal stake (separate from the drafting eligibility threshold; a curator with s_i < L who cannot be drafted may still appeal). The appeal triggers a new round with a larger drafted committee at higher stakes. The appeal committee independently scores the same claim under the same policy. If the appeal committee’s weighted mean differs from the original round’s mean by more than a pool-configurable threshold, the appeal succeeds: the appeal score replaces the original, and original-round curators whose scores were closer to the overturned mean than to the appeal mean are slashed. If the difference is within the threshold, the appeal fails and the appellant’s stake is slashed. Multiple escalation rounds may occur, each with a larger committee and higher cost, up to a pool-configurable maximum depth.
The primary function of escalation is not the appeal itself but its threat. First-round curators who anticipate that a lazy or biased score could be overturned by a larger, better-informed appeal committee have an incentive to score carefully from the start. The Schelling focal point shifts from “converge with what the current committee will vote” to “converge with what would survive appeal.” Under a continuous-signal model in which each distinct curator observes an unbiased signal of the policy-implied latent relevance, signals are independent or only weakly dependent, and signal variance is finite, the weighted mean concentrates around that latent target as the number of distinct curators grows under bounded weight concentration. In the seat-based draft model, increasing seats alone is not sufficient: multiple seats held by one curator still map to a single revealed score. Subject to that qualifier, a larger and less concentrated appeal court is the higher-accuracy anchor. This gives a well-informed minority a credible path to overturn a lazy majority: they appeal, a larger committee with more distinct curators is drawn, and the outcome moves toward the policy-faithful score.

This design keeps curation entirely stake-driven: no reputation-weighted mechanism influences either drafting or voting. That is a major departure from the earlier design.
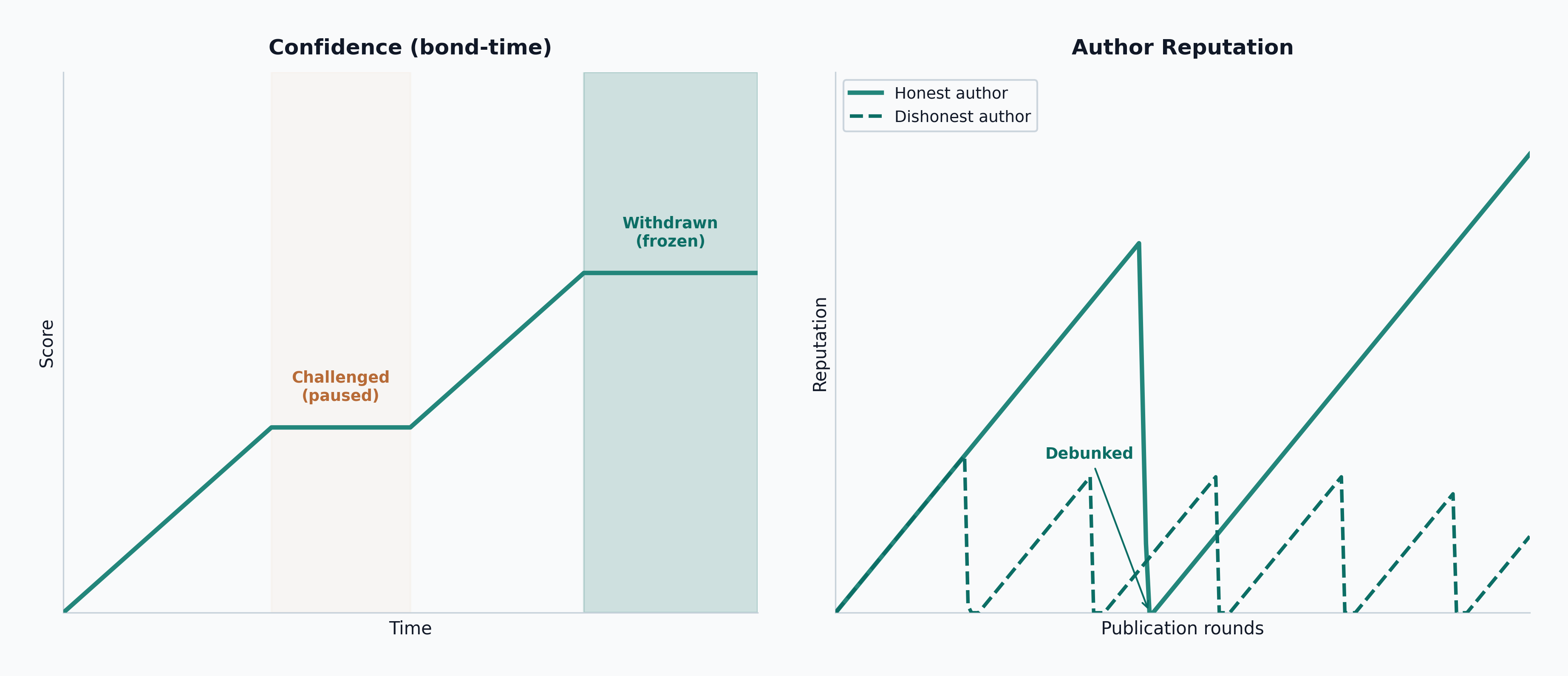
5.6 Confidence
Confidence is not a truth label. It is accumulated bond-time. Let C denote the resulting confidence score, let B_t denote the bond active during interval \Delta t, and let the summation run over the item’s bonded history:
C = \sum_t B_t \cdot \Delta t
The semantics are simple:
- larger bond means more capital at risk
- longer survival means longer exposure to challenge
- challenge pauses accumulation; a successful defense resumes accrual from the paused integral
- amendment (
PendingEdit -> Live) resets confidence to zero, since the content has changed - withdrawal freezes the score permanently
An interface may use confidence for ranking or display, but it must not conflate confidence with a universal truth claim. Confidence measures accumulated capital risk exposure over time, not community validation or endorsement. The scrutiny signal is survival: a Live item that has survived an explicit challenge attempt carries stronger evidence of accuracy than one that has simply accumulated bond-time without being tested. Figure 7 illustrates these dynamics.
There is therefore no protocol-level dollar cutoff at which a claim becomes “noise.” Confidence is continuous. A low-bond claim simply carries weak evidence because little capital is at risk and, by Claim 1, the bond is too small to deter high-value deception unless it exceeds the value at stake. Interfaces may impose additional visibility thresholds, but those thresholds are downstream product policy rather than validated protocol constants.
5.7 Reputation
The current design uses a single reputation system:
- Author reputation is a pool-scoped, slowly decaying credibility stock. It is not escrowed per claim, but every new claim exposes the author’s standing reputation to large downside if the claim is debunked. A reputation update caused by one claim does not affect the confidence or relevance of the author’s other claims; each claim continues under its own bond-time history.
The design deliberately avoids any reputation-weighted mechanism for curation. An earlier iteration allowed reputation to directly increase curation weight; the current design rejects that entirely because it grants influence not fully backed by slashable capital. Curation drafting and voting are both purely stake-driven.
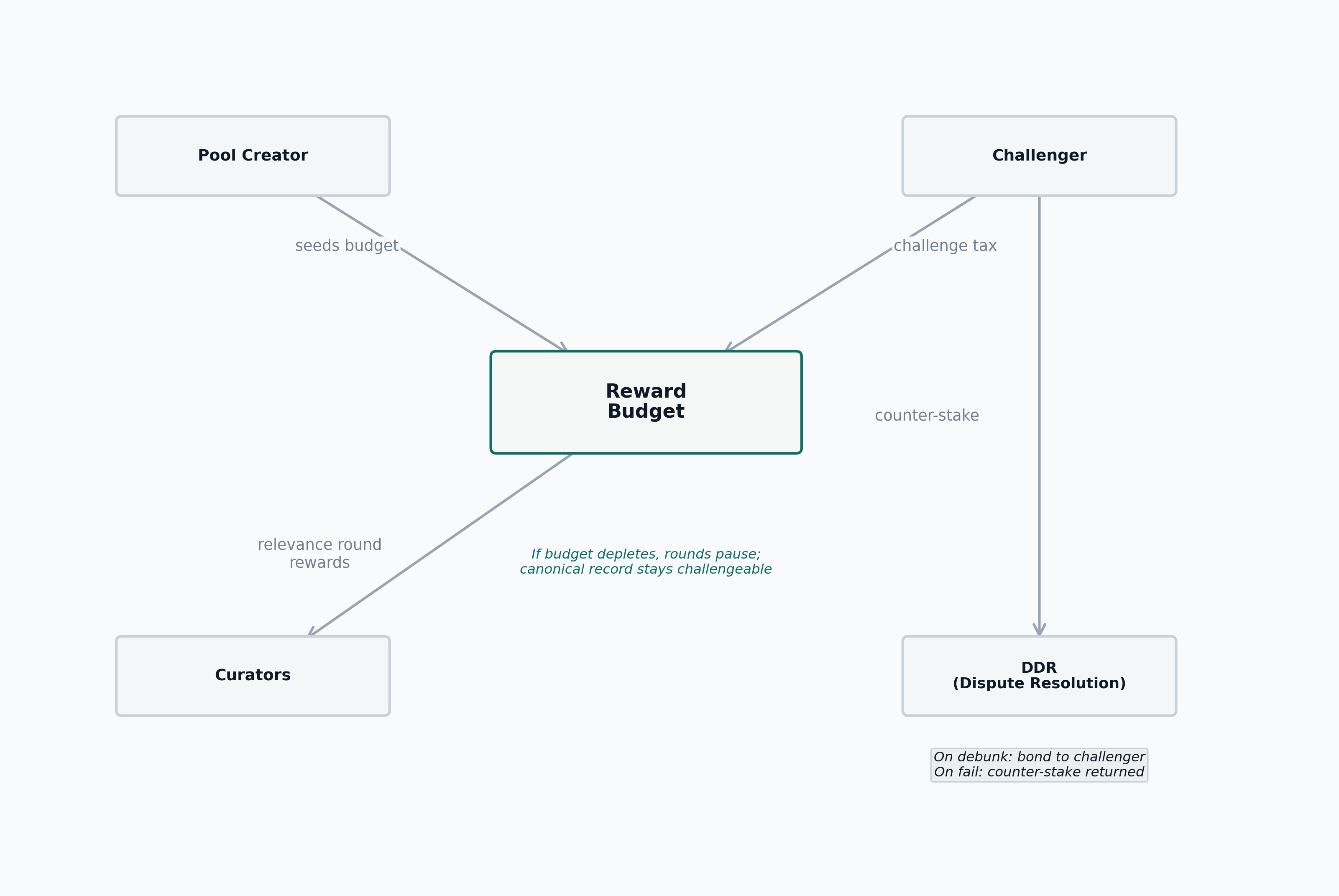
5.8 Local pool economics
Each pool has its own reward budget (Figure 8). The pool creator or any sponsor can top it up. Relevance-round reward floors are paid from that local budget, not from a vague global treasury. If the budget runs dry, new relevance rounds pause; the canonical record remains challengeable.
Challenge tax is paid by the challenger and routed to the challenged pool’s reward budget. For immediately active challenges, the tax credits at filing; for queued challenges, the tax remains in escrow until activation and is refunded if the challenge is cancelled or mooted by an earlier debunking. On a failed challenge, the pool-budget share of the challenger’s counter-stake (determined by the pool’s payout-split ratio) also credits the pool. Both inflows are dispute-dependent: a peaceful pool generates zero endogenous revenue. This makes pool economics local rather than governance-allocated, but also makes peacetime funding entirely sponsor-dependent.
6 Equilibrium Analysis
This section develops stylized equilibrium claims for the protocol’s core mechanisms. The algebra below derives threshold conditions in simplified expected-value models, but the labeled claims are not presented as formal theorems with full proofs. They should be read as model-based conditions under which honest strategies are rational, and as markers for where those conditions can fail.
6.2 Challenger’s entry decision
A challenger does not arrive with a known false claim. They must search. Let e denote the effort cost of examining one claim, let \beta denote the base rate of false claims in the pool, let p_{\text{detect|examined}} denote the probability that examination reveals falsity, and let \text{EV}_{\text{false}} denote the challenger’s expected value on a known false claim from the accuracy layer. The expected value of examining one claim is:
\text{EV}_{\text{search}} = \beta \cdot p_{\text{detect|examined}} \cdot \text{EV}_{\text{false}} - e
Searching is profitable when:
\beta > \beta^* = \frac{e}{p_{\text{detect|examined}} \cdot \text{EV}_{\text{false}}}
Claim 2. Challenger entry is rational only when the false-claim base rate \beta exceeds \beta^*. Below this threshold, no rational agent searches, and the system enters a no-challenge equilibrium. This is not a protocol failure when \beta is genuinely low: a pool with few false claims does not need active challengers. The risk is that \beta rises undetected because no one is looking.
The free-rider dimension compounds this problem (Groves and Ledyard 1977). A challenger who debunks a false claim produces a public good (a cleaner pool), but bears the full search cost privately. Challenge rewards partially internalize this externality, but the first-mover disadvantage in search remains: rational challengers wait for others to search first.
6.3 Curator voting strategy
The coherence game requires curators to independently report relevance scores in [0, 1]. Under commit-reveal, curators cannot observe others’ votes before committing. Each curator i has a private signal \theta_i about the true relevance r and forms a belief about the distribution of others’ signals. Here r denotes the latent relevance value implied by the pool policy, \theta_i denotes curator i’s noisy private estimate of that value, K is the coherence-threshold multiplier from the slashing rule, and \phi^* denotes the largest colluding stake fraction under which honest reporting remains stable.
Claim 3. Under the coherence mechanism with commit-reveal, honest reporting is a Bayesian Nash equilibrium when the following conditions hold simultaneously:
(i) The curation policy is specific enough that all competent curators’ private signals \theta_i are distributed around the true relevance r with bounded variance.
(ii) The coherence threshold K is large enough that honest reports within normal signal noise are not slashed.
(iii) The fraction of deviating curators is below a collusion threshold \phi^* such that the weighted mean remains close to r.
When condition (iii) fails, a coalition of fraction \phi > \phi^* that coordinates on a biased report shifts the weighted mean toward the coalition’s target. Honest reporters may then fall outside the coherence band and be slashed, while dishonest reporters survive. At this point, honest voting ceases to be a best response.
The collusion threshold \phi^* depends on the committee size, the coherence threshold K, honest curator noise \sigma_{\text{honest}}, and colluder strategy. E2-Adv characterizes this threshold empirically under the predecessor mechanism (fixed-rate binary slashing, no draw-and-lock): at K = 1.25 with 15-member committees, the mechanism degrades visibly when the colluding fraction exceeds approximately 0.15 to 0.20. E2’ (see Section 9.4) re-runs the same sweep under the final mechanism (draw-and-lock seat allocation, graduated slashing, ambiguity-driven abstention) and reports the corresponding \phi^* in parallel. The sensitivity of \phi^* to \sigma_{\text{honest}} is characterized in the E2’-Adv \sigma sweep (Figure 19): higher honest noise narrows the gap between legitimate disagreement and colluder bias, compressing the detection margin. The Trojan accumulation experiment (Figure 20) tests whether colluders who build stake before attacking can amplify their terminal position; under the tested parameters, delayed onset is strictly worse for the attacker. The \phi^* \approx 0.15–0.20 range is specific to the tested configuration (K = 1.25, 15-seat committees, \sigma_{\text{honest}} = 0.08, constant +0.30 bias) and is a simulation-derived bound, not a structural theorem.
George’s impossibility result constrains what can be claimed here (George 2023b). For games with three or more ranked alternatives and minimal attack resistance, truthful reporting cannot always be a Nash equilibrium. The coherence game escapes this impossibility because curators report on a continuous scalar aggregated by weighted mean with a deviation penalty, not a ranking over discrete alternatives. The game structure is formally different from the ranked-alternative games covered by the impossibility. This escape is defensible but structural rather than airtight: the impossibility does not directly bind, but the coherence game is not immune to all strategic manipulation.
The theoretical structure of the escape deserves scrutiny. For single-peaked preferences on a single dimension, the generalized median mechanism is strategyproof: no individual voter can benefit from misreporting (Moulin 1980). The coherence game operates on the same single dimension (relevance in [0, 1]). If curators’ preferences are single-peaked around their true signal, the comparison to Moulin’s result applies. However, the aggregation rule is the stake-weighted mean, not the median. The mean is manipulable: any individual curator can shift it by reporting an extreme value. The graduated K\sigma coherence band partially compensates by imposing losses that scale with deviation distance, making unilateral extreme-value manipulation costly. But the band does not prevent a coordinated coalition from shifting the mean itself: if enough curators agree on a biased target, the mean moves toward the target and the coalition stays inside the band while honest reporters may fall outside it. This is exactly the failure mode E2-Adv characterizes. Escalation compensates where the band cannot: a coordinated coalition that shifts the mean in round 1 faces a larger appeal committee where sampling variance is reduced, making overrepresentation from lucky draws less likely and the committee mean more reflective of the pool’s true stake-weighted distribution. This helps when the coalition is a stake minority in the pool; a coalition with majority stake dominates committees of any size. The residual defense for that case is economic: a majority-stake attacker who distorts a pool’s curation output degrades the pool’s utility, driving users and curators to competing pools and reducing the value of the attacker’s locked position. This argument holds for profit-seeking attackers whose locked capital exceeds the external value of capturing the pool; it does not hold for externally motivated attackers (state actors, competitors) who treat the stake as an operational expense. The formal escape from George’s impossibility (continuous scalars, not ranked alternatives) coexists with a distinct manipulability gap: the weighted mean is vulnerable to coalition coordination, but the combination of graduated slashing and escalation narrows the attack surface to coordinated coalitions exceeding a measurable stake threshold \phi^* across multiple committee sizes.
Relevance-round escalation changes the equilibrium analysis. Without escalation, curators converge on “what the current committee will vote,” which is vulnerable to lazy or coordinated majorities that exceed \phi^* within the committee. With escalation, the focal point shifts to “what would survive appeal by a larger committee.” Under the same continuous-signal assumptions, the appeal-round mean concentrates more tightly around the latent relevance target only when escalation increases the number of distinct drafted curators; additional seats assigned to the same curator do not create new independent observations, and concentrated stake can still dominate the weighted mean. A dissenting minority that believes the first-round score is wrong can appeal; if the appeal committee agrees with the minority, the original majority is slashed. The threat of this outcome disciplines first-round curators to score carefully rather than lazily. Escalation replaces per-identity weight caps as the defense against whale manipulation: a dishonest whale who dominates round 1 by locking many seats faces proportionally larger losses on appeal when the appeal round broadens independent participation enough to reduce the weighted mean’s variance and overturn the original score. This defense is effective when the whale is a stake minority; a majority-stake whale dominates any committee size. The residual defense is economic rather than mechanical: distorting a pool’s output degrades its utility and the attacker’s locked capital with it, which deters profit-seeking attackers but not externally motivated ones. The effective \phi^* rises because a colluding bloc must be large enough to survive not only the current round but also a potential appeal round with a larger committee. The formal conditions under which escalation shifts the equilibrium are a design argument under these signal-aggregation assumptions, not a proven theorem; simulation of escalation dynamics is future work. A potential refinement is a meta-prediction layer: curators commit a predicted \sigma alongside their score, scored with a proper scoring rule. This is one plausible single-round signal that partially separates lazy convergence from genuine consensus, since informed curators who expect genuine agreement predict low \sigma for the right reasons while lazy curators predict low \sigma trivially. The feasibility and collusion resistance of meta-prediction in a blockchain commit-reveal setting are open questions.
The majority-stake case deserves explicit treatment because no on-chain mechanism prevents it. If staking uses a platform-specific token with limited circulating supply, accumulating a majority position is superlinear in cost: each additional token purchased costs more than the last due to slippage on a thin order book, and the accumulation itself produces a visible price signal that alerts the community. The attack is doubly self-defeating: the attacker pays a slippage premium to enter, then the captured pool’s degradation depresses the token’s value, compounding losses. By contrast, if staking uses a deep-market token like ETH, the attacker can accumulate with negligible slippage and the token’s value is independent of this protocol’s health, removing the depreciation feedback loop. Permissionless pool creation bounds the blast radius: capture of one pool does not compromise others, and users can migrate at the cost of rebuilding confidence history. The residual risk is real for externally motivated attackers (state actors, political operatives) who treat locked capital as an operational expense rather than an investment. No permissionless system resolves majority-stake capture without introducing identity requirements, which would sacrifice the permissionless property that makes pool creation and competitive exit viable in the first place.
6.4 Participation equilibrium
The system requires authors, challengers, and curators. Each faces a participation decision against an outside option of doing nothing.
Claim 4. A participation equilibrium exists when:
(i) Author entry: honest authors’ expected returns (confidence accumulation, reputation) exceed the opportunity cost of bonded capital.
(ii) Challenger entry: the false-claim base rate \beta exceeds \beta^*, making search profitable.
(iii) Curator entry: the per-round expected reward for coherent curators exceeds the opportunity cost of staked capital.
The most fragile condition is challenger entry. If \beta drops below \beta^*, challengers exit. Their exit may allow \beta to rise, creating a cyclical dynamic rather than a stable equilibrium.
This cyclical risk is bounded in practice. Some challengers are motivated beyond pure expected value: journalistic reputation, ideological commitment, or interface-level bounties. These non-economic motivations dampen the exit cycle. But the protocol design should not depend on altruism; the bond and reward parameters must make participation viable for rational actors under reasonable assumptions.
8 Threat Model
The protocol assumes adversaries can be rational, coordinated, well-funded, and persistent. The table below summarizes the principal attacks and their design responses; the paragraphs that follow explain why each response works.
| Attack | Design response |
|---|---|
| False claims survive because challenging is uneconomic | Bonded publication plus debunking rewards |
| Colluding curators try to bend relevance | Drafted committees, draw-and-lock with graduated slashing, relevance-round escalation |
| Non-falsifiable or vague claims exploit semantic ambiguity | Structured claim templates plus NonFalsifiable challenge reason |
| Off-topic claims pollute a pool | ScopeViolation challenge reason for topic mismatch |
| Claims bypass template rules via direct contract interaction | On-chain structural validation at submission; TemplateViolation challenge reason for semantic non-conformance |
| Bad pools set degenerate policies or parameters | Permissionless competition plus interface filtering rather than governance veto |
| A dominant frontend recentralizes discovery | Canonical protocol state and replaceable interfaces |
| Reputation creates unbonded influence | No reputation-weighted curation mechanism exists; author reputation is a separate standing bond only |
| Low-participation pools fail to bootstrap | Pool creators seed local reward budgets; interfaces can ignore inactive pools |
| Stale claims linger forever | Confidence only accumulates while bonded; withdrawn claims remain historical rather than active |
| Permissionless publishing surfaces harmful or illegal content | Protocol is content-neutral; interfaces filter according to local norms and legal requirements |
| An ideological pool curates biased content under a permissive policy | Accuracy is adjudicated cross-pool by DDR regardless of pool membership; biased relevance is local and subject to competitive exit |
| Curators converge on conventional wisdom, suppressing nuanced truth | Reduced low-dispersion rewards plus escalation threat; appeal to a larger committee disciplines first-round scoring |
False-claim survival. Bonded publication forces the author to lock capital that a successful challenger captures. Claim 1 derives the bond threshold B^* above which false publication has negative expected value as a function of detection coverage; E1 validates the economics across the parameter range. The deterrence strength scales with detection coverage rather than with a fixed bond multiple.
Curator collusion. A colluding bloc that coordinates scores can shift the weighted mean and slash honest reporters who fall outside the coherence band. Commit-reveal prevents real-time vote copying; draw-and-lock randomizes committee composition, making targeted bribery harder because the attacker does not know which curators will be drafted; graduated slashing raises the minimum bribe needed to cover deviation cost. Claim 3 identifies the collusion threshold \phi^* conceptually, and E2-Adv and Section 9.4 estimate its location empirically at approximately 0.15 to 0.20 for 15-member committees.
Non-falsifiable claims. A vague or unfalsifiable claim is harder to catch through binary Debunking adjudication because jurors have weaker grounds to rule against a proposition that is not clearly false, only ill-posed. The NonFalsifiable challenge reason routes such claims to adjudication on falsifiability rather than truth, where the question is whether the proposition meets the pool’s template and evidence-policy requirements. E3 quantifies the retention-cost reduction as a function of prevalence and the adjudication-accuracy gap between dedicated falsifiability review and forced-binary truth adjudication.
Off-topic claims. A claim may be well-formed and factually defensible but belong to the wrong topic domain. The ScopeViolation challenge reason lets any participant flag domain mismatch post-publication, routing adjudication to the question of whether the claim falls within the pool’s declared scope rather than whether it is true.
Template-violating claims. On-chain structural validation at submission enforces minimal field presence (non-empty CIDs, valid version pointers), but a claim can pass those checks while still violating the pool’s semantic template requirements: disallowed source classes, missing required evidence fields, or incorrect formatting. The TemplateViolation challenge reason enforces these semantic constraints post-publication without requiring computationally expensive on-chain content analysis at submission time.
Bad pools. Permissionless pool creation means degenerate policies cannot be prevented at the protocol level. The defense is competitive: a pool with a trivial policy produces undifferentiated scores that no one values, while a pool with adversarial templates deters authors from publishing. Users migrate to better-curated alternatives. This defense is market-based and assumes sufficient alternatives and low switching costs; its limitations are discussed in the boundary conditions.
Frontend recentralization. Protocol state is canonical and publicly readable on-chain. A biased interface can choose what to surface but cannot falsify protocol outputs. Because any party can build a competing interface against the same canonical state, a dominant frontend that censors or distorts faces competition from transparent alternatives. The barrier to entry is building an interface, not gaining permission.
Reputation as unbonded influence. An earlier design allowed accumulated curator reputation to increase curation weight, granting influence not backed by slashable capital. The current design eliminates reputation-weighted curation entirely. Drafting and voting are purely stake-driven: influence requires locking capital at risk, and there is no mechanism through which historical performance translates into unslashable voting power.
Bootstrap failure. A new pool needs authors, challengers, curators, and a reward budget simultaneously. Pool creators seed local reward budgets to attract initial curators, and the accuracy layer functions independently of the relevance layer: bonded claims are challengeable even before any relevance round runs. Claim 4 models the participation equilibrium and identifies challenger entry as the most fragile condition, with a cyclical dynamic when the false-claim base rate falls below the search-profitability threshold.
Stale claims. Confidence keeps accumulating as long as a claim remains bonded and Live, so the protocol does not cut off value at any age. The incentive to withdraw an obsolete claim is twofold: the bonded capital has an opportunity cost (it could be redeployed to a new claim), and as the underlying facts change, the claim faces growing challenge risk from anyone who can demonstrate its falsity under new evidence. An author who withdraws freezes confidence permanently and recovers the bond.
Harmful content. The protocol does not perform content moderation because it has no content-level semantics: canonical state records bonds, challenges, and scores, not rendered text. Interfaces, which do render content, filter according to their own policies and local legal requirements. This is the same separation that operates in other permissionless systems: the transport layer is neutral, and the application layer applies editorial judgment. The limitation is that the defense depends on interface-level action; a negligent or complicit interface can surface harmful content without violating any protocol rule.
Ideological echo chambers. A pool whose policy permits biased curation can produce biased relevance scores, and the coherence game will faithfully enforce that bias as long as curators agree. The accuracy layer operates cross-pool: any bonded claim is challengeable regardless of which pool it appears in, so factually false claims cannot be sheltered by a sympathetic pool policy. Biased relevance, however, is local to the pool; the defense against it is user exit to competing pools with stricter or different policies, not intra-pool correction.
Lazy-consensus convergence. The coherence game rewards agreement with the committee mean, which can reward convergence on conventional wisdom even when the crowd is systematically wrong. This is distinct from active collusion: no coordination is required for curators to independently anchor on a lazy prior. When curators converge tightly, \sigma drops and the graduated slashing rule is skipped, so the mechanism does not directly penalize a lazy majority that agrees on the wrong answer. Two defenses remain: first, low-\sigma rounds pay reduced rewards (scaled by \sigma / \sigma_{\mathrm{ref}}), making lazy convergence less profitable than informed disagreement; second, a dissenting minority can appeal to a larger committee where sampling variance is lower and the mean concentrates more tightly around the policy-implied target, with the threat of overturn and slashing disciplining first-round curators. The residual risk is that when the crowd’s prior is uniformly biased, escalation produces a larger committee with the same bias; this limitation is discussed in the boundary conditions.
Several threats remain partially unresolved: off-chain collusion, legal pressure against visible participants, pool-policy degeneracy, coordinated capture above a sufficiently large colluding bloc, lazy-consensus convergence when the crowd is systematically wrong, and free-rider extraction of canonical on-chain state by third-party aggregators.
9 Evaluation
The evaluation suite is a conditional viability analysis: it maps which regions of parameter space sustain each mechanism and which break it, rather than predicting where a live deployment will land. No parameter is empirically calibrated; each is swept across a range wide enough to span optimistic and pessimistic scenarios. The results establish that if detection coverage, juror accuracy, and honest-curator noise fall within identified viable ranges, the mechanism’s incentive structure holds. They do not establish that any particular deployment will occupy those ranges. Calibrating the parameters requires live-pool data that does not yet exist (challenger activity logs for p_{\text{detect}}, Kleros case outcomes for p_{\text{juror}}, observed curator score distributions for \sigma_{\text{honest}}).
The suite focuses on four questions:
- When is it economically rational to challenge false claims?
- How robust is drafted-curator relevance curation to noise and collusion?
- What follows if a dedicated
NonFalsifiablechallenge reason materially improves adjudication accuracy on otherwise non-falsifiable claims? - Does author reputation as a standing bond create useful separation between honest and dishonest publishers, and does pool scoping prevent credibility earned in one pool from carrying into another?
| Parameter | Value | Role | Source | Calibration status |
|---|---|---|---|---|
| p_{\text{juror}} | 0.80 (swept 0.50–0.90) | Per-juror accuracy in DDR panels | Kleros design estimate | Unvalidated; swept |
| p_{\text{detect}} | 0.35 anchor (swept 0.05–0.80) | Probability a false claim is discovered and challenged | Illustrative anchor | Unvalidated; swept |
| K | 1.25 | Coherence-band multiplier (K\sigma) | Reference parameter | Unvalidated; fixed |
| \sigma_{\text{honest}} | 0.10 | Standard deviation of honest curator scores | Assumed moderate noise | Unvalidated; fixed |
| \varphi^* | \approx 0.15–0.20 | Collusion fraction at which relevance degrades | Empirical from E2/E2’ | Simulation-derived; not a theorem |
| \delta | 0.01/round | Author reputation decay rate | Assumed | Unvalidated; fixed |
| f | 0.25 | Non-falsifiable claim prevalence (E3 only) | Assumed | Unvalidated; scenario input |
| p_{\text{nf}} | 0.85 | Juror accuracy on NonFalsifiable challenges (E3 only) | Assumed | Unvalidated; scenario input |
| N | 5 | Jurors per dispute panel | Kleros default | Partially validated (Kleros operational) |
9.0.1 Evaluation snapshot (representative points)
- E1 (primary result): Holding p=0.80 and N=5 fixed, single-window false-claim survival falls from 0.95 at p_\mathrm{detect}=0.05 down to 0.25 at p_\mathrm{detect}=0.80, and the deterrence threshold B^*/V falls from 20.2 down to 0.3 over the same sweep. Intermediate points: survival is 0.91 at p_\mathrm{detect}=0.10 (B^*/V=9.6), 0.67 at p_\mathrm{detect}=0.35 (B^*/V=2.0), and 0.53 at p_\mathrm{detect}=0.50 (B^*/V=1.1).
- E1 (challenger economics, illustrative anchor p_\mathrm{detect}=0.35): At p=0.80, N=5, S/B=0.25, challenger EV on a debunking challenge is 0.872 \pm 0.001bounty (95% CI, N=100 seeds) after tax and DDR fees, and simulated one-window survival at this anchor is 0.670 \pm 0.002.
- E2: At initial competence 0.70 and K=1.25, mean relevance error is 0.072 \pm 0.001 (95% CI, N=100 seeds), cancelled-round share is 0.000 \pm 0.000, and final competent stake share is 0.75 \pm 0.00.
- E3: Closed-form scenario analysis only. At non-falsifiable share 0.25, bad-item retention is 0.12 under an illustrative forced-binary assumption of p=0.55 versus 0.03 when a dedicated
NonFalsifiablechallenge reason raises the assumed per-juror accuracy to p=0.85. - E1-Adv: A well-funded adversary submitting 50 false claims at p=0.80 and illustrative anchor p_\mathrm{detect}=0.35 achieves survival rate 0.67 \pm 0.01 (95% CI, N=100 seeds) with cumulative balance -1734 \pm 72.
- E2-Adv (predecessor mechanism): A 15% colluding bloc shifts mean relevance error from 0.095 to 0.111 \pm 0.001 and ends with 0.146 \pm 0.000 stake share.
- E2’-Adv (final mechanism): Under draw-and-lock + graduated slashing + ambiguity abstention, a 15% colluding bloc shifts mean relevance error from 0.081 to 0.104 \pm 0.001 and ends with 0.149 \pm 0.003 stake share.
- E2’-Adv \sigma sweep: At \phi=0.15, mean relevance error is 0.099 \pm 0.001 at \sigma_{\text{honest}}=0.05 versus 0.123 \pm 0.002 at \sigma_{\text{honest}}=0.20 (95% CI, N=100 seeds). Higher honest noise makes collusion harder to distinguish from legitimate disagreement.
- E2’-Adv Trojan: At \phi=0.15, each delay gets 200 attack rounds (total rounds = T + 200). Final colluder stake share at T=0: 0.148 \pm 0.003; at T=100: 0.100 \pm 0.005 (95% CI, N=100 seeds). Delayed onset leaves colluders with less terminal stake than attacking immediately.
- E4a: By round 120, median honest-author reputation reaches 8.84 \pm 0.11 (95% CI, N=100 seeds) while median dishonest-author reputation remains at 0.24 \pm 0.02.
- E4b: In a counterfactual reputation-weighted committee with decay \delta=0.01, a random high-reputation attacker stays above median weight for 87 \pm 1 rounds, while a +0.15 strategic-bias attacker lasts 100 \pm 1 rounds and shifts the final signal upward by 0.008 \pm 0.000.
- E4d: After building reputation in Pool L, an unscoped attacker enters Pool H with 26.35 \pm 1.62 imported reputation units (95% CI, N=200 seeds); over the first 10 attack rounds, mean attacker share of Pool H author reputation is 0.008 \pm 0.001 unscoped versus 0.001 \pm 0.000 when reputation is pool-scoped, and the imported advantage decays to within 0.10 reputation units after 10.2 \pm 0.2 attack rounds.
9.1 Deployment evidence (Truth Post 2023)
Truth Post launched in 2023 as a partial instantiation implementing the accuracy layer only: bonded publication, challenge filing, and Kleros-routed dispute resolution. It omitted the relevance layer, curator pools, local reward budgets, multi-interface architecture, and the full confidence and reputation system. As of April 9, 2026, the deployed contract recorded 16 external transactions (five article initializations, three bounty increases, six withdrawal-related transactions, one ownership transfer, one admin change) and no visible challenge transaction.
The deployment established three things: first, the bonded-publication architecture and Kleros dispute path were deployable on existing infrastructure; second, the MVP omitted too much of the end-state design to test the full thesis; third, a decentralized protocol with a single fragile frontend is not actually robust. Truth Post does not validate the whole system. It validates that this work has crossed the boundary from abstract idea to deployment, failure, and redesign.
9.2 E1: Accuracy challenge economics
The accuracy layer is economically useful only if challenging false claims can be rational. We model a challenger who pays counter-stake S = \max(\text{pool minimum}, B/4), challenge tax \tau (a pool-configurable percentage of the pinned bond), and DDR fee f to attack an item with author bond B. All challenge economics reference the bond at filing time, so later bond adjustments do not alter the dispute’s economic basis. Let P_{\mathrm{maj}}(p, N) be the probability that a jury of size N returns the correct binary outcome when each juror is correct with probability p. Challenger expected value on a false claim is:
\mathrm{EV}_{\mathrm{false}} = P_{\mathrm{maj}}(p, N)\cdot(B - \tau - f) + (1-P_{\mathrm{maj}}(p, N))\cdot(-S - \tau - f)
This quantity is conditional on a challenger having already found a false claim worth disputing. In the present reduced-form model, p_{\text{detect}} does not enter \mathrm{EV}_{\mathrm{false}} directly because detection determines whether a challenge opportunity materializes at all, not the payoff of a known debunking case once filed.
Figure Figure 9 shows that conditional challenger EV becomes strongly positive across the tested stake-to-bounty ratios once juror accuracy moves into plausible territory. Figure Figure 10 reports the headline accuracy-layer result: single-window false-claim survival as a function of detection coverage p_{\text{detect}} \in [0.05, 0.80], holding p=0.80 and N=5 fixed. Figure Figure 11 then holds p_{\text{detect}}=0.35 fixed as an illustrative anchor and varies juror accuracy to show the residual dependence on p; each plotted point is estimated from 100 seeded batches of repeated challenge windows, so the bands quantify stochastic execution noise in the simulated challenge process, not uncertainty about the closed-form incentive equations themselves.
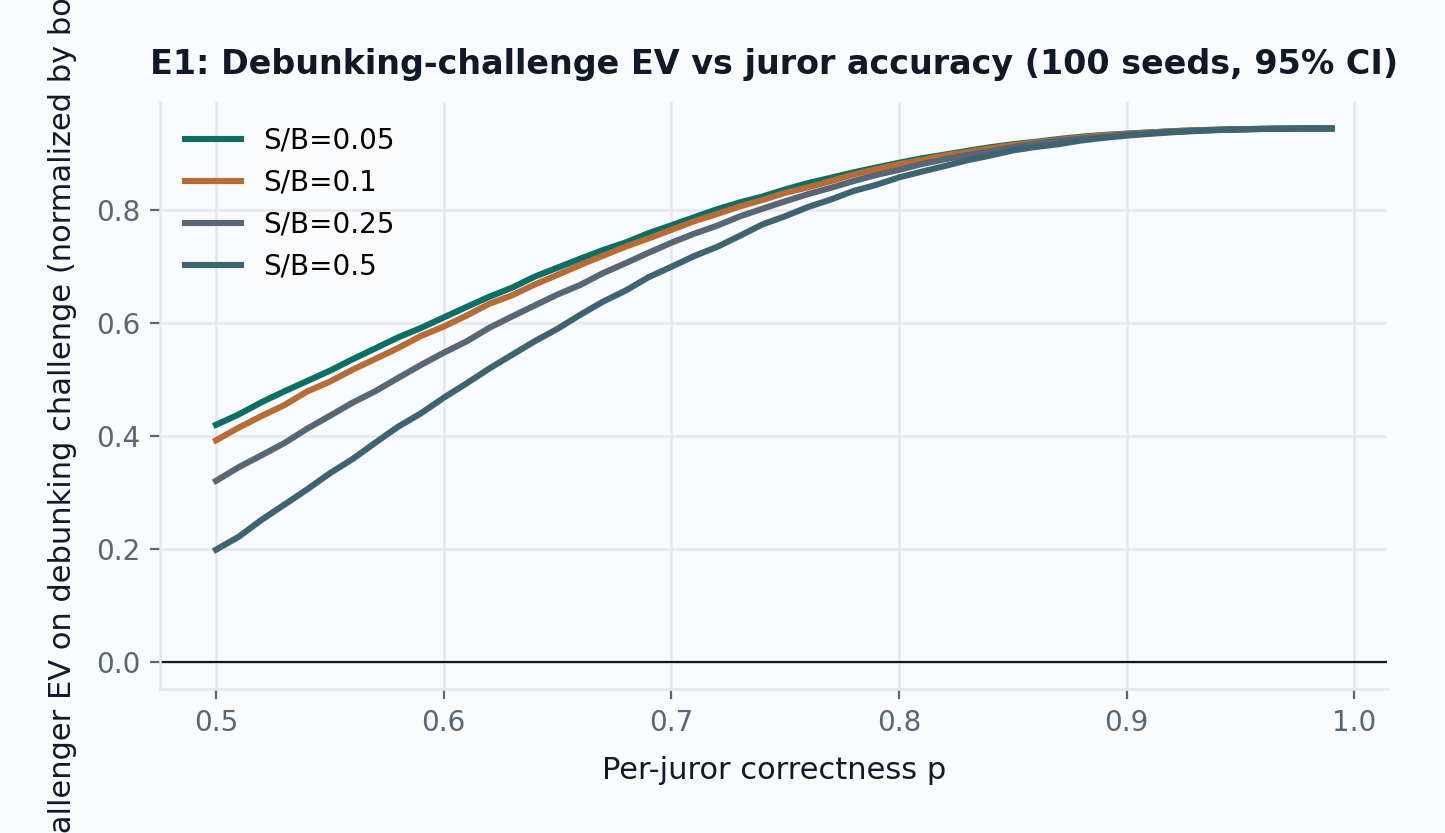
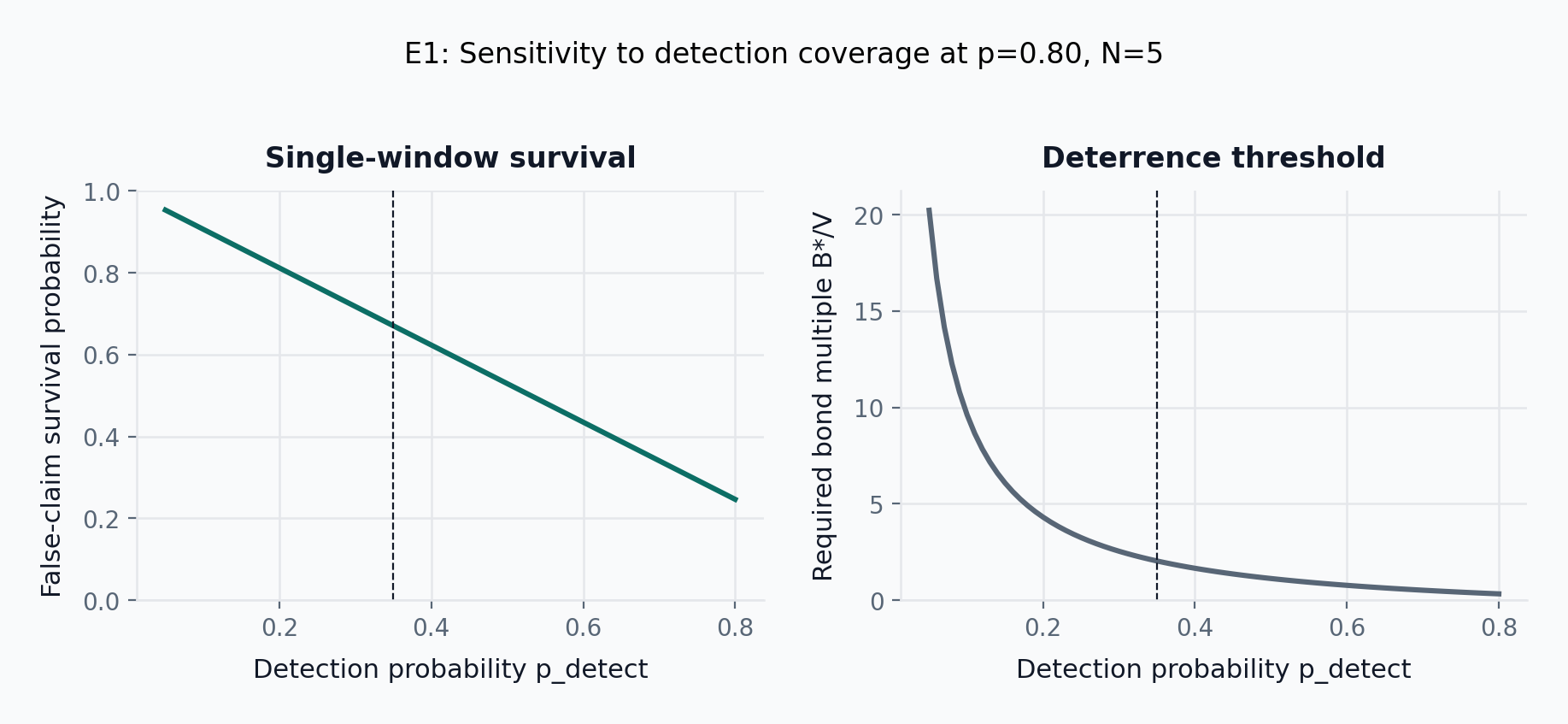
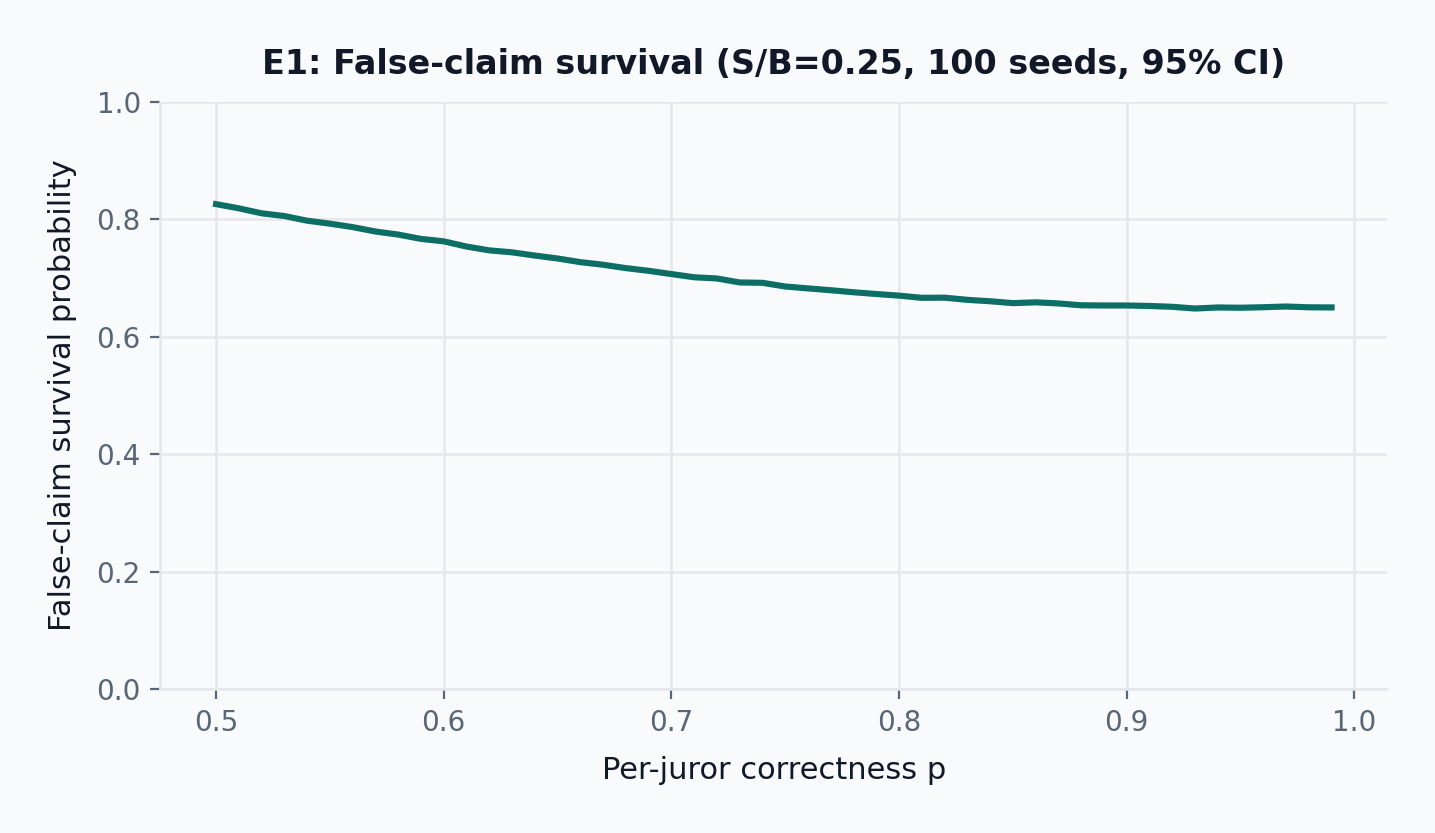
Figure Figure 10 reports the primary accuracy-layer finding directly. At p=0.80 and N=5, single-window false-claim survival falls monotonically from about 0.95 at p_{\text{detect}}=0.05 to 0.91 at 0.10, 0.67 at 0.35, 0.53 at 0.50, and 0.25 at 0.80. Over the same range, the deterrence threshold B^*/V falls from roughly 20 to 0.3. The accuracy layer therefore does not bind the paper to any single survival estimate; it binds detection coverage to a well-defined tradeoff curve with the author bond. At the illustrative p_{\text{detect}}=0.35 anchor, a challenge at S/B=0.25 yields roughly 0.87\times bounty expected value for the challenger while false-claim survival is approximately 0.67 after one window; this point is used for cross-referencing later claims, not as the result the paper argues for. Detection coverage, not jury math alone, is the first-order viability condition.
In practice, p varies by claim difficulty: straightforward factual claims are easier to adjudicate than nuanced or context-dependent ones. The commit-reveal protocol enforces vote secrecy during the commitment phase, preventing direct vote-copying, but does not guarantee epistemic independence: jurors who share information sources, follow the same public commentary, or coordinate off-chain will have positively correlated signals. The P_{\text{maj}} formula assumes independent juror accuracy, so it may overestimate panel correctness when signal correlation is high. The sweep across p values partially compensates by letting the reader assess performance at lower effective accuracy levels, which can be interpreted as a proxy for correlated-signal regimes.
Bond size is itself the incentive for scrutiny. High-bond items attract challengers because the potential reward justifies the investigation cost; low-bond items attract less scrutiny but also carry proportionally less confidence. In this sense, p_{\text{detect}} is not fully exogenous: it scales with bond size, since larger rewards draw more attention. The current paper does not endogenize that mapping; it treats p_{\text{detect}} as a reduced-form coverage parameter and tests sensitivity rather than claiming empirical calibration. Items that receive insufficient scrutiny also accumulate insufficient confidence, making the two signals coherent.
9.2.1 E1-Adv: repeated false-claim attacks
Single-claim economics are insufficient. A real adversary can submit many false claims. E1-Adv therefore simulates a well-funded attacker submitting 50 false items under varying juror accuracy, holding p_{\text{detect}}=0.35 fixed as an illustrative anchor so the adversarial result is directly comparable to the single-window point at the same anchor; the detection-coverage sweep in Figure 10 remains the primary first-order result.
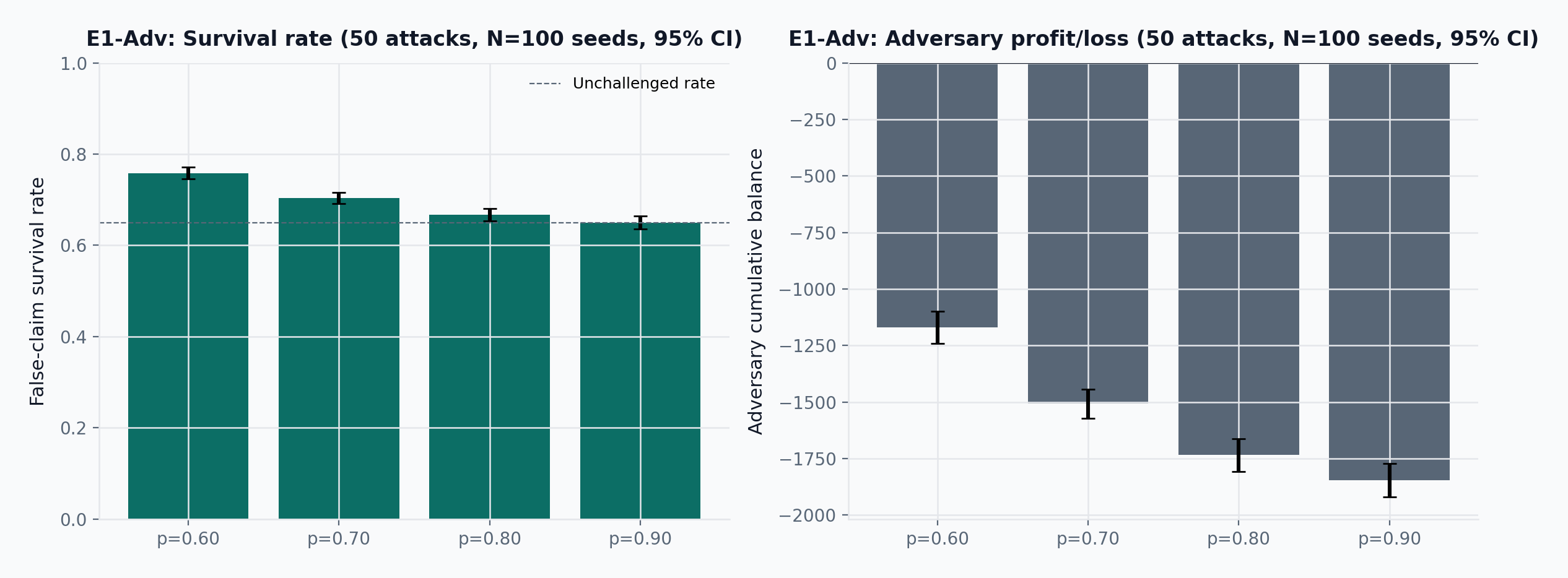
The result is economically punitive. At p=0.80, the adversary’s cumulative balance is deeply negative. Volume does not rescue the attacker; it compounds losses once a sufficient fraction of claims are detected and correctly debunked.
9.3 E2: Relevance with drafted curators
E2 evaluates the relevance layer under a simplified predecessor model: curators are drafted into committees from a larger pool using purely stake-weighted selection with the per-identity weight cap disabled. The current design replaces weight caps with draw-and-lock seat allocation and graduated slashing; E2 retains the predecessor model for comparison, and E2’ (below) re-runs the same sweeps under the final mechanism. Here \mu denotes the weighted mean of committee scores, \sigma denotes the weighted standard deviation, and K denotes the coherence-threshold multiplier used in the slashing rule. In the E2 simulation, degenerate rounds (\sigma below flat_round_stddev_min) are treated as cancelled and excluded from scoring; the current design instead accepts the mean as a valid score, skips graduated slashing only when \sigma < \varepsilon_\sigma, and computes rewards via f_{\mathrm{reward}} (the \rho-offset linear scaling defined in step 6). This is a simulation-vs-design gap: E2 results reflect the cancellation model, not the guarded smooth reward-scaling model.
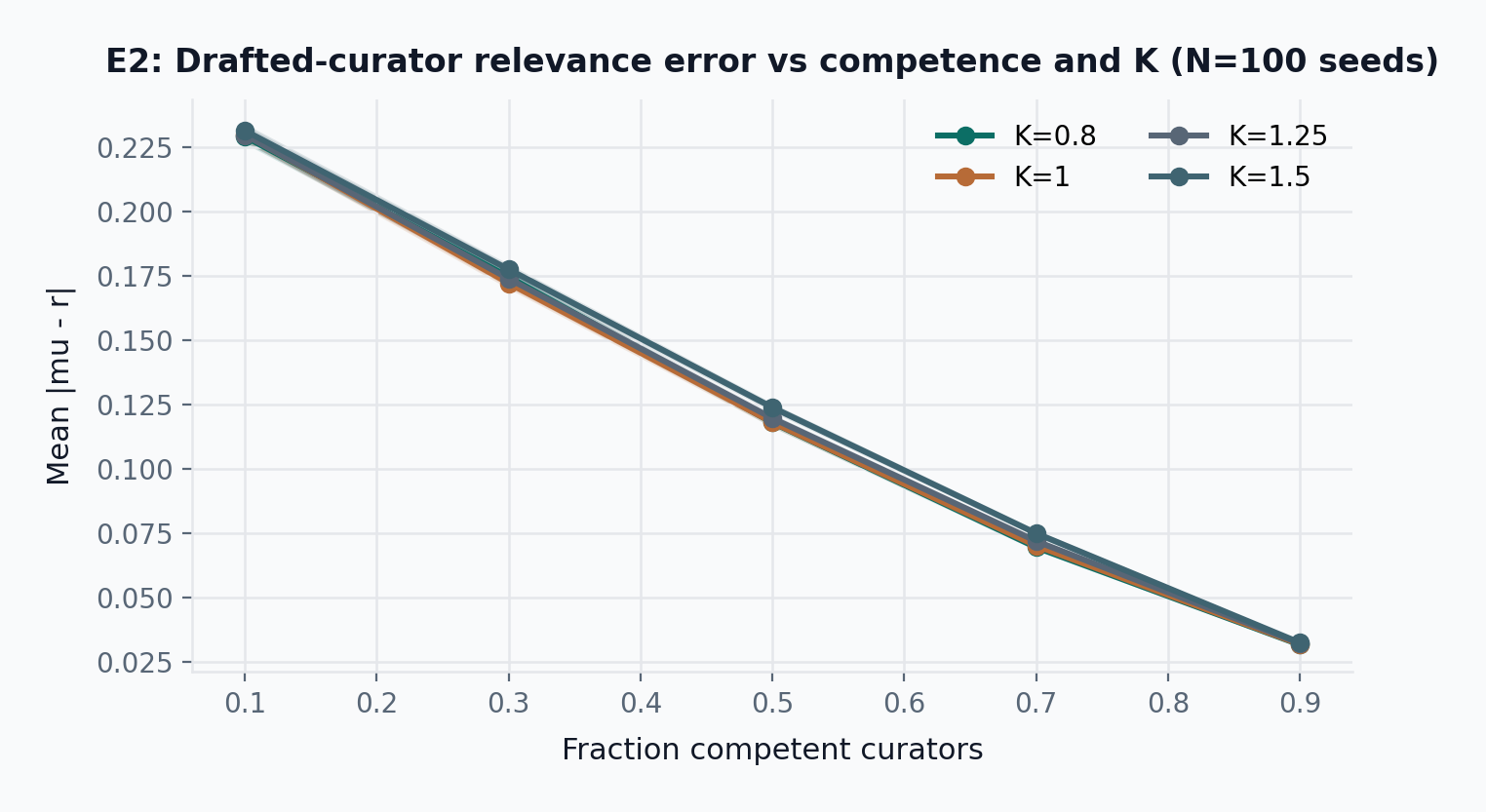
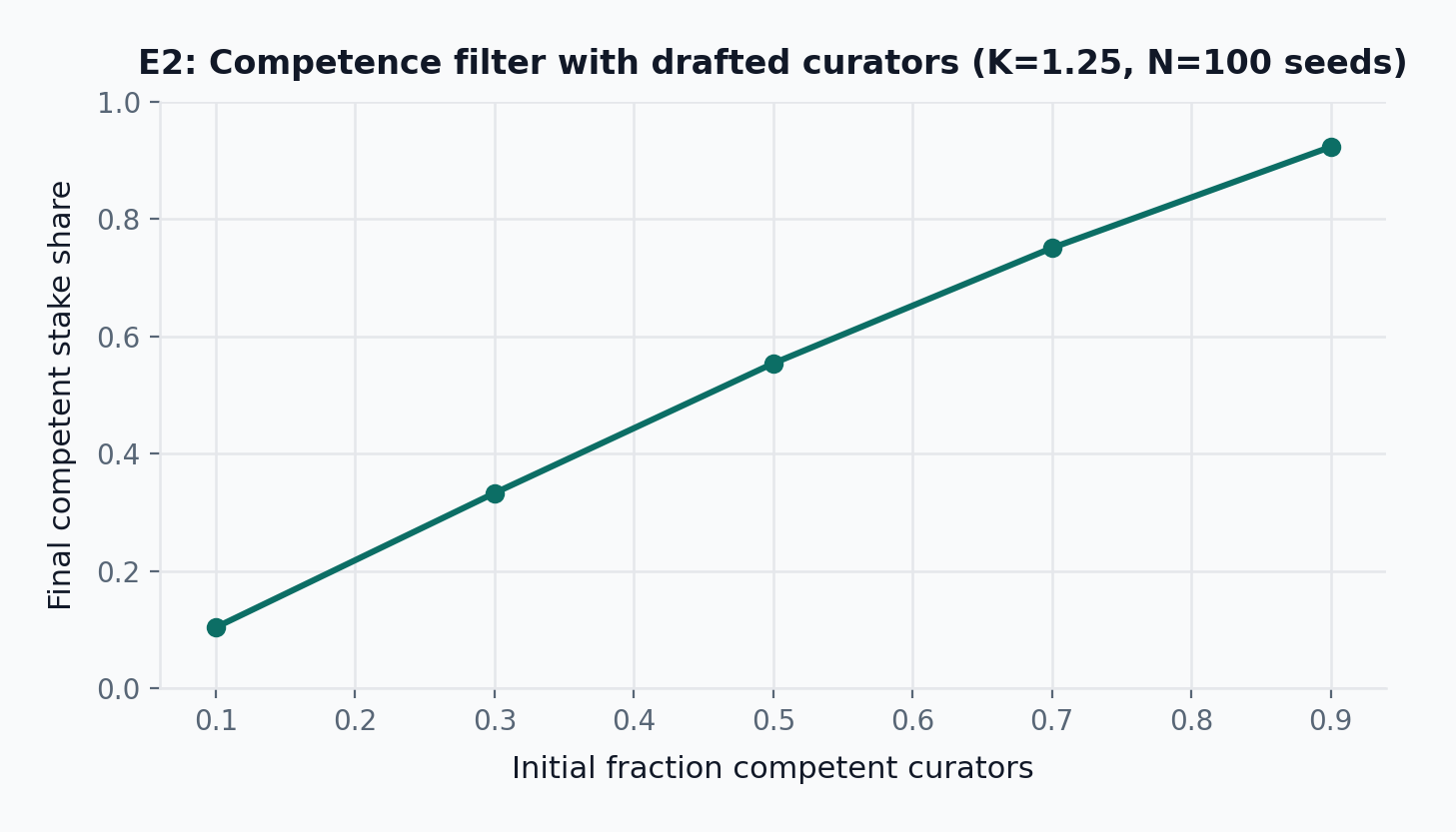
The results preserve the desired qualitative behavior. When competent curators dominate, relevance error falls and competent stake accumulates. Error bands show 95% confidence intervals over 100 seeds; the evaluation snapshot reports mean error and competent stake share with confidence intervals at the representative point. This is not a theorem of truth; it is a competence filter under a public policy.
9.3.1 E2-Adv: colluding curators
E2-Adv introduces a colluding bloc of competent-but-biased curators. They vote coherently, but in the wrong direction, and try to survive by redefining the apparent consensus.
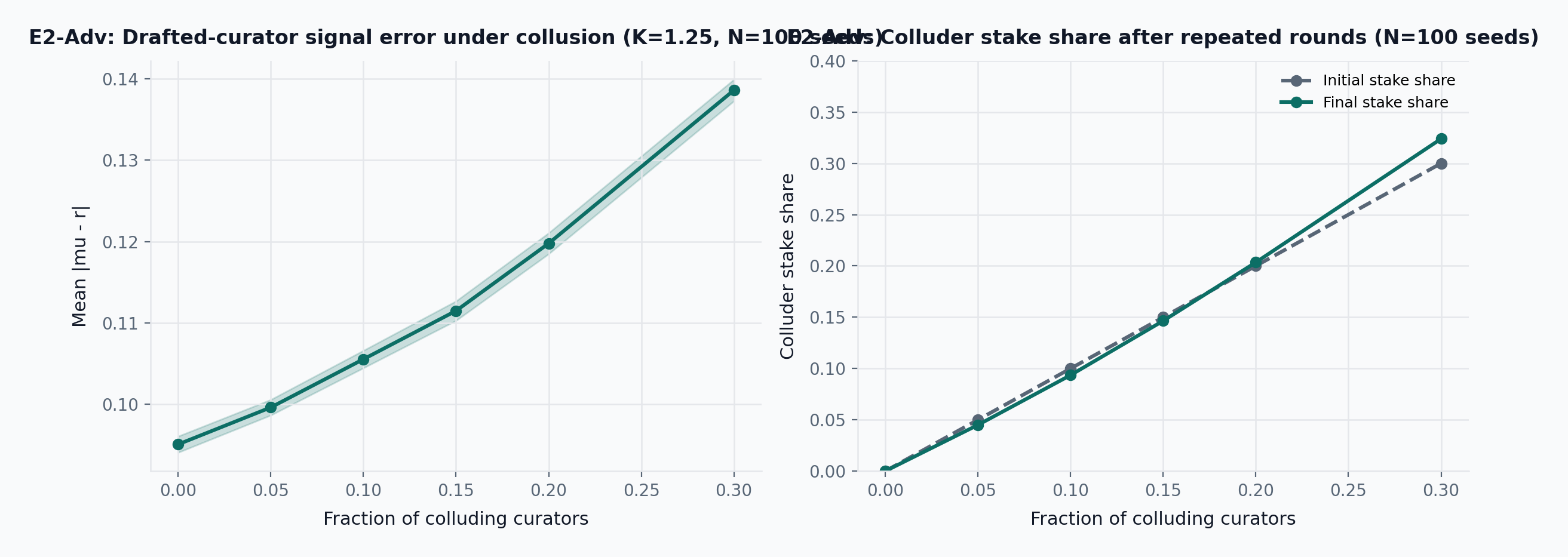
The mechanism behaves as expected: small colluding minorities cause limited damage and do not expand much, but sufficiently large coordinated blocs begin to bend the signal and preserve their own stake. The current design does not eliminate this risk. It narrows the attack surface relative to the older reputation-weighted voting model by keeping all curation mechanics purely stake-driven.
9.4 E2’: Relevance under the final mechanism
E2 and E2-Adv report the predecessor mechanism (fixed-rate binary slashing, no seat-ticket draw-and-lock). E2’ re-runs the same sweeps under the final relevance mechanism specified in the Equilibrium Analysis section above and in projects/truth-post/blueprint.md §Flow F: each curator i receives seat-tickets d_i = \lfloor s_i / L \rfloor, the scheduler draws n seats without replacement from the ticket pool, each drawn ticket locks L tokens, and graduated slashing follows p_i = \min(1, \max(0, (|v_i - \mu|/\sigma - K)/K)) with the \sigma < \varepsilon_\sigma guard. E2’ additionally models a hidden per-round ambiguity flag: each drafted curator draws a noisy signal correlated with the flag and may abstain; if the share of abstainers among distinct drafted curators exceeds a strict-majority cutoff (0.5 in the present parameterization, i.e., more abstainers than non-abstainers) the round cancels, and individual abstainers lose their locked tokens per blueprint step 11.
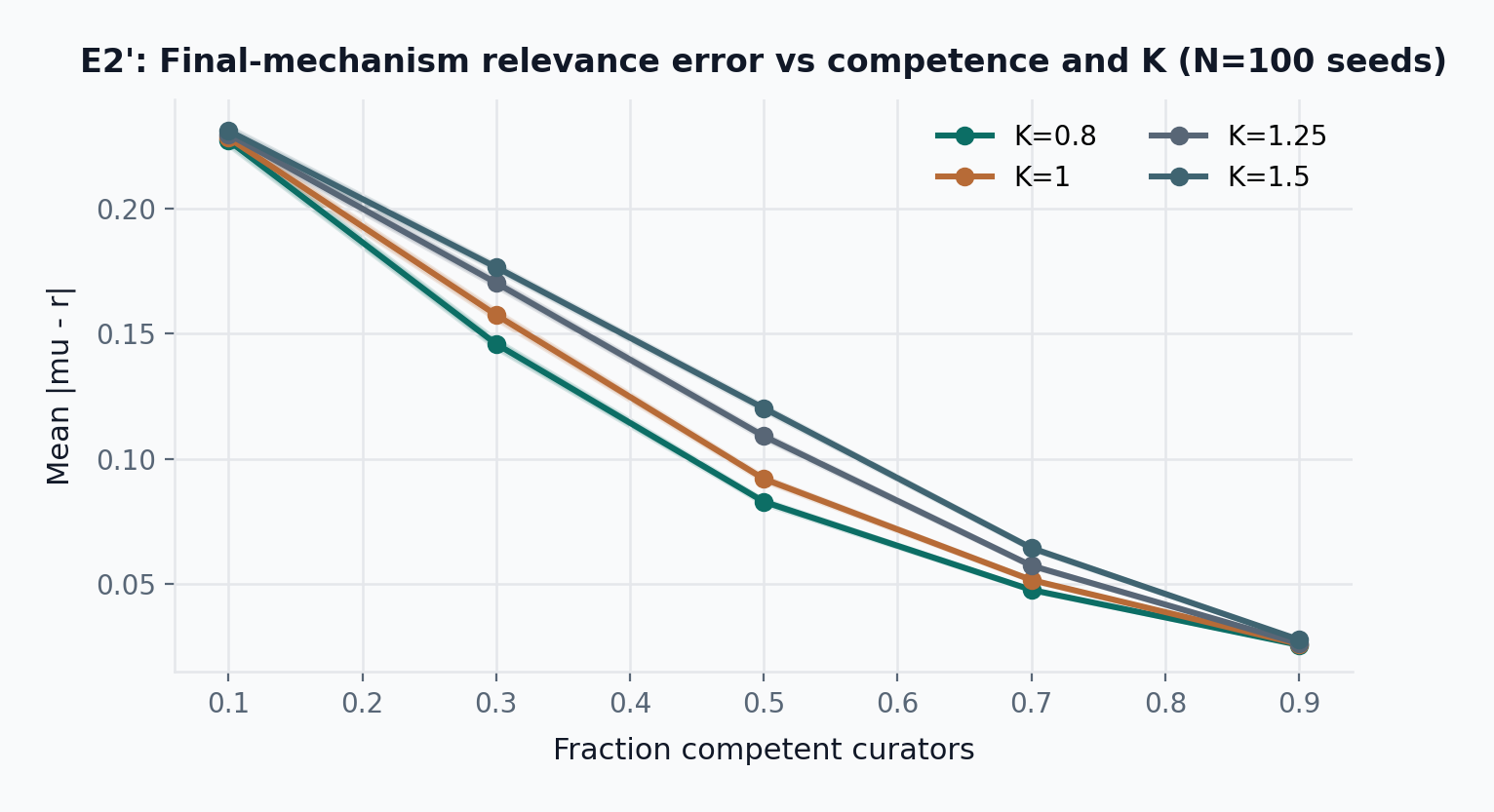
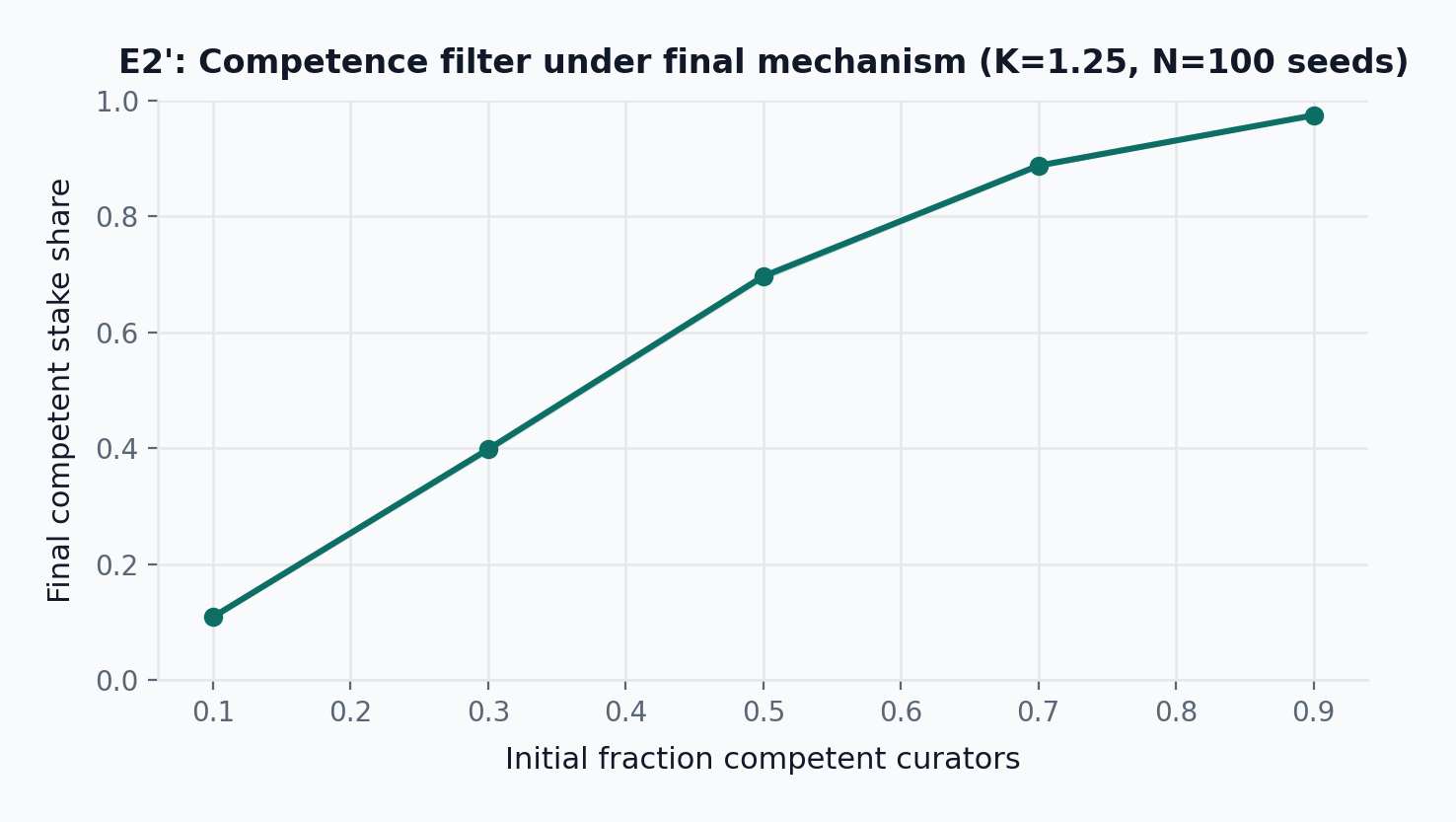
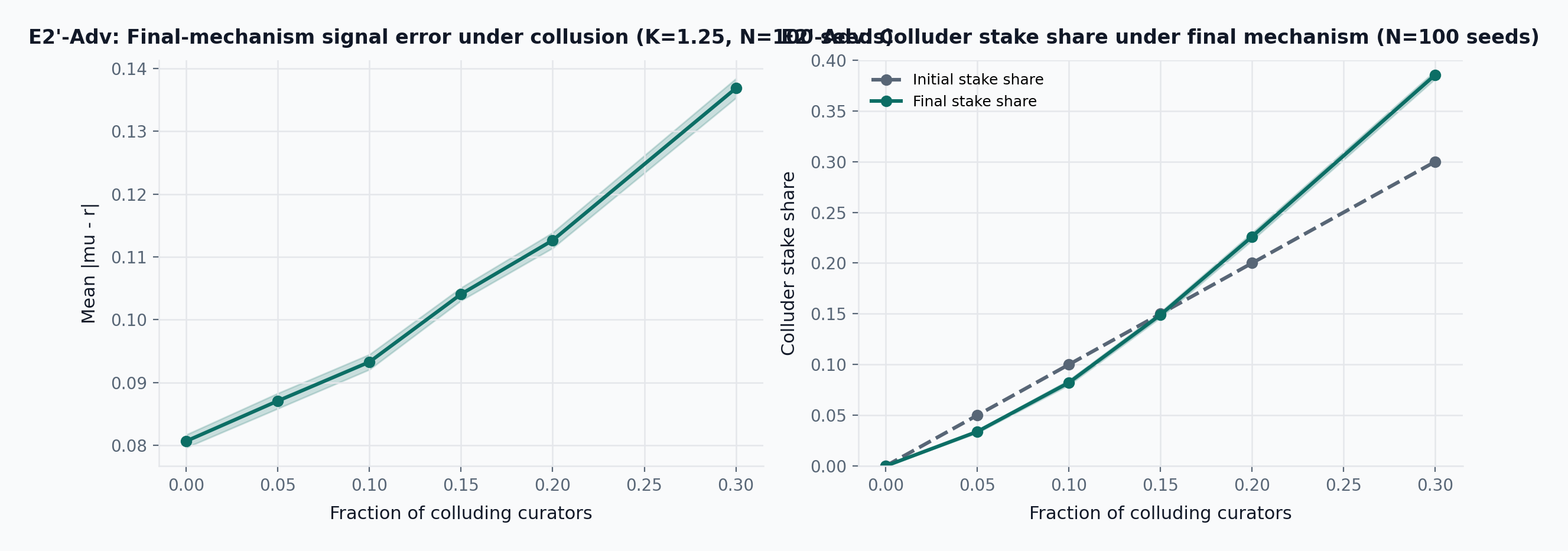
Under E2’-Adv at K=1.25 with 15-seat committees, mean relevance error rises from 0.081 at \phi=0 to 0.104 at \phi=0.15, 0.113 at \phi=0.20, and 0.137 at \phi=0.30. The same qualitative break as predecessor E2-Adv appears in roughly the same band (\phi^* \approx 0.15 to 0.20), consistent with the equilibrium argument in Claim 3: the decisive quantity is whether a colluding bloc is large enough to shift the weighted mean by more than the coherence band half-width, which is a function of K and committee size rather than of the slashing functional form. Graduated slashing permits higher terminal colluder stake at the same \phi (0.226 at \phi=0.20 vs 0.203 under E2-Adv) because near-boundary deviations incur only partial loss, but the mean-error curve is not worse and is slightly better at every tested \phi. Under the tested parameters with the ambiguity layer enabled, roughly 15 percent of rounds cancel via the strict-majority abstention threshold and the mean error on non-cancelled rounds does not increase materially. A direct ablation comparing with-ambiguity and no-ambiguity runs to isolate the ambiguity layer’s specific contribution is future work. These results should be read as a corroboration, not a recalibration, of the predecessor \phi^* estimate.
9.4.1 E2’-Adv \sigma sweep: sensitivity of \phi^* to honest curator noise
The preceding collusion sweeps fix \sigma_{\text{honest}} = 0.08. The collusion threshold \phi^* depends on the gap between honest noise and colluder deviation: at low \sigma_{\text{honest}}, a +0.30 bias stands out sharply; at high \sigma_{\text{honest}}, honest disagreement overlaps with colluder bias, making collusion harder to distinguish. To characterize this dependence, we repeat the full E2’-Adv collusion sweep at \sigma_{\text{honest}} \in \{0.05, 0.08, 0.10, 0.12, 0.15, 0.20\}.
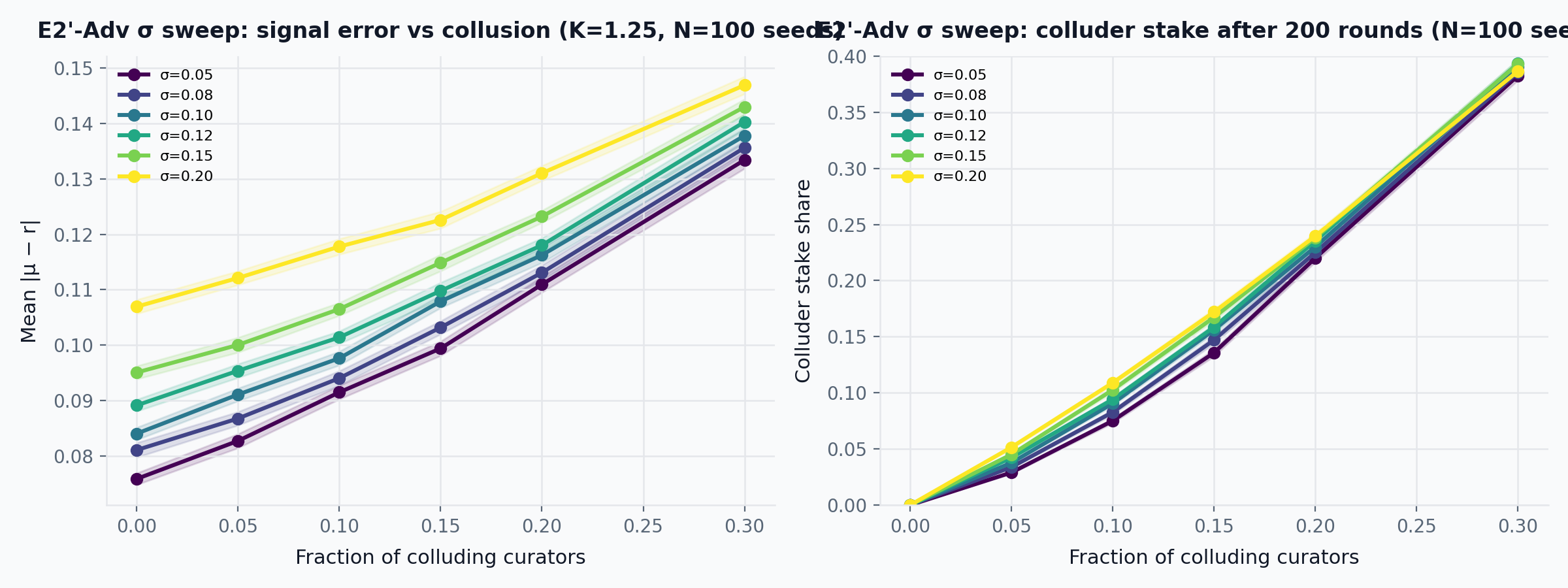
At \phi = 0.15, mean relevance error ranges from 0.099 at \sigma_{\text{honest}} = 0.05 to 0.123 at \sigma_{\text{honest}} = 0.20, a 24% increase. The baseline error (no collusion) rises from 0.076 to 0.107 over the same range, so the incremental error from a 15% colluding bloc shrinks from 0.024 to 0.016. Colluder stake shares at \phi = 0.30 converge across all \sigma values (0.38–0.39), indicating that at high collusion fractions the slashing mechanism operates on deviation distance regardless of noise level. The practical implication: \phi^* \approx 0.15–0.20 is robust when the colluder bias (+0.30) substantially exceeds honest noise, but the detection margin narrows as \sigma_{\text{honest}} approaches the bias magnitude.
9.4.2 E2’-Adv Trojan accumulation: delayed-onset collusion
The constant-bias collusion model assumes colluders attack from round 1. A more strategic adversary might behave honestly for T rounds to accumulate stake through coherence rewards, then switch to biased reporting. To isolate the accumulation effect from the confound of fewer attack rounds, total simulation length is T + 200: every delay value gets 200 attack rounds, and only the honest lead-in varies. We test at \phi = 0.15 with delays T \in \{0, 25, 50, 100\}.
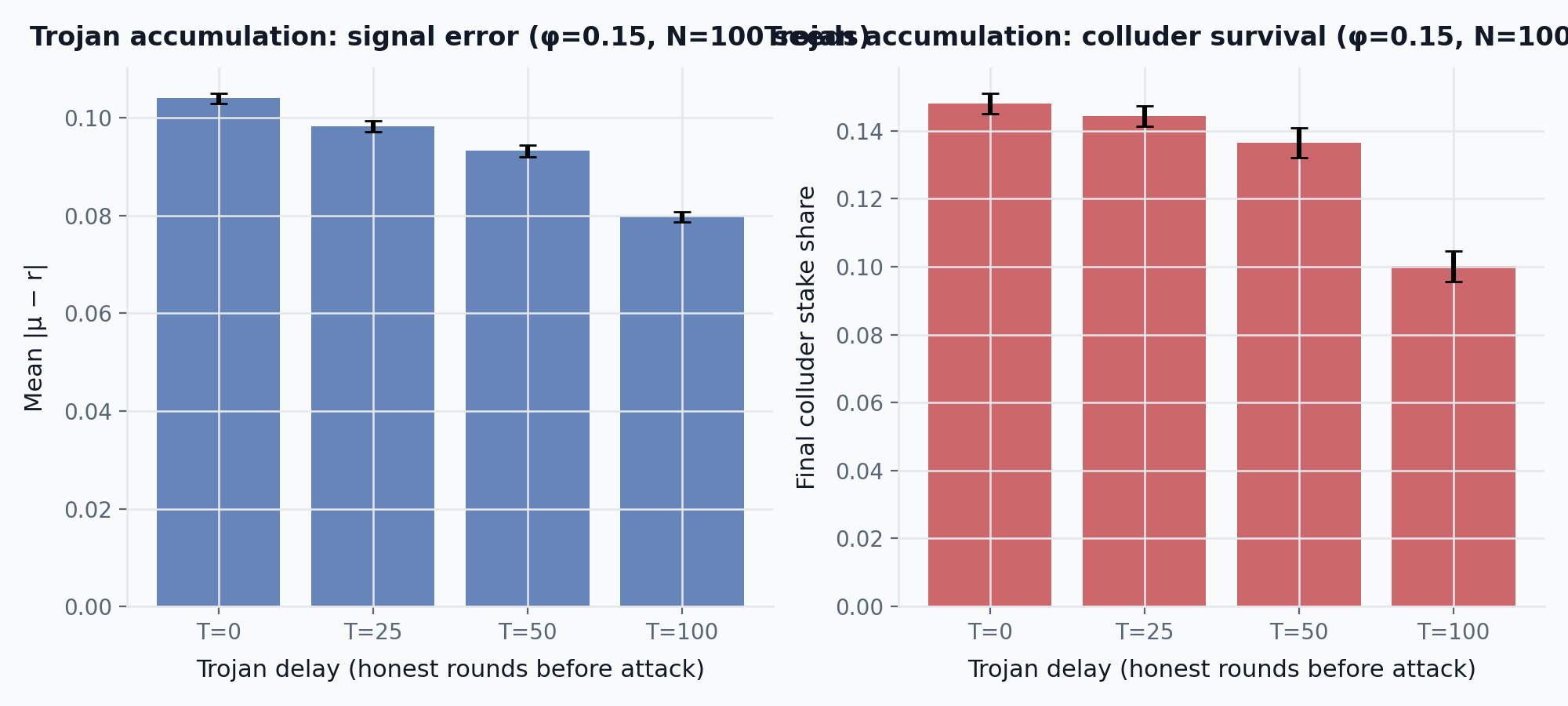
The comparable metric is final colluder stake share, which measures the same terminal snapshot regardless of simulation length. Final colluder stake share decreases with longer delay (0.148 at T = 0 vs 0.100 at T = 100): honest-phase stake accumulation exists but is more than offset by the additional rounds of stake redistribution that dilute the colluding bloc’s position. Whole-run mean error also falls (0.104 at T = 0 vs 0.080 at T = 100), but this metric averages over T + 200 total rounds and is therefore not directly comparable across delay values; the drop reflects honest rounds diluting the average rather than a weaker attack phase. At \phi = 0.15 under these parameters, delayed-onset collusion leaves colluders with less terminal stake than attacking immediately. Testing whether this result holds at higher collusion fractions or with adaptive bias strategies that ramp gradually rather than switching abruptly is a natural extension.
9.5 E3: Dedicated NonFalsifiable challenges
An earlier version of this manuscript evaluated a third verdict label for ambiguous claims. The current design is different. A non-falsifiable or badly specified proposition should not receive its own truth-status output; it should be challengeable, and a successful challenge should debunk the item.
E3 is not a stochastic simulation like E1, E2, or E4. It is a closed-form scenario analysis that isolates one design question: what happens if non-falsifiable bad items are forced through ordinary binary adjudication rather than given a dedicated NonFalsifiable challenge reason?
Let f denote the share of bad items that are non-falsifiable, let P_{\mathrm{maj}}(p, N) denote majority correctness for a jury of size N with per-juror correctness p, let p_{\mathrm{false}} denote juror accuracy on ordinary false claims, let p_{\mathrm{binary}} denote juror accuracy when a non-falsifiable proposition is nevertheless forced into binary adjudication, and let p_{\mathrm{NF}} denote juror accuracy when the same proposition can be challenged under a dedicated NonFalsifiable reason. Then bad-item retention is:
R_{\mathrm{binary}}(f) = (1-f)\left[1 - P_{\mathrm{maj}}(p_{\mathrm{false}}, N)\right] + f\left[1 - P_{\mathrm{maj}}(p_{\mathrm{binary}}, N)\right]
R_{\mathrm{NF}}(f) = (1-f)\left[1 - P_{\mathrm{maj}}(p_{\mathrm{false}}, N)\right] + f\left[1 - P_{\mathrm{maj}}(p_{\mathrm{NF}}, N)\right]
The retention reduction is therefore:
R_{\mathrm{binary}}(f) - R_{\mathrm{NF}}(f) = f \left[P_{\mathrm{maj}}(p_{\mathrm{NF}}, N) - P_{\mathrm{maj}}(p_{\mathrm{binary}}, N)\right]
The point of E3 is exactly this dependency structure. The benefit scales linearly with two assumptions: how often bad items are non-falsifiable, and how much a dedicated challenge reason improves adjudication accuracy on that subset.
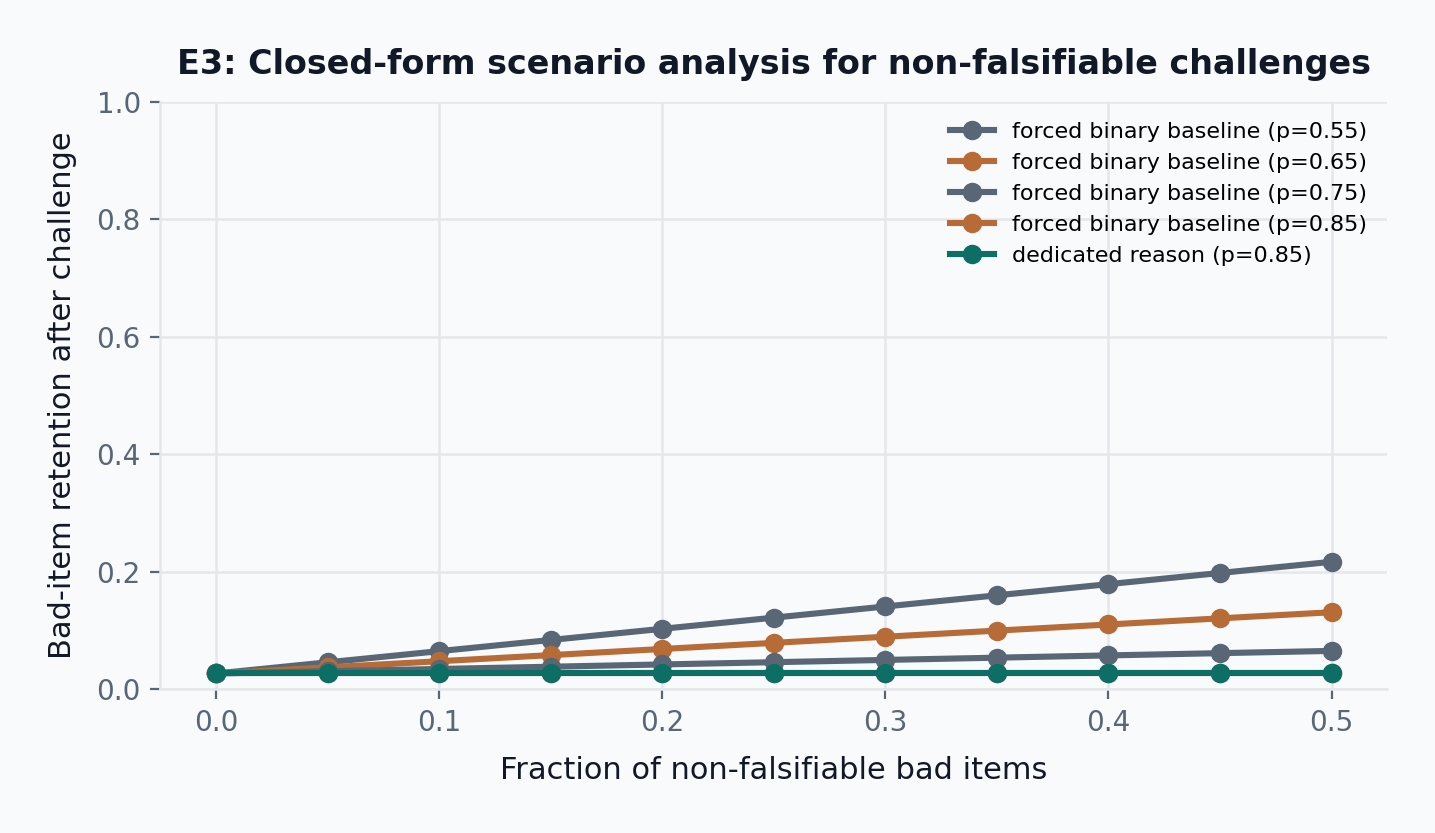
Figure Figure 21 makes the what-if nature explicit. The defended line fixes p_{\mathrm{false}} = p_{\mathrm{NF}} = 0.85 and then varies the forced-binary assumption for the non-falsifiable subset. At 25% non-falsifiable prevalence, bad-item retention is 0.12 under the pessimistic illustrative case p_{\mathrm{binary}} = 0.55, 0.08 at p_{\mathrm{binary}} = 0.65, and 0.05 at p_{\mathrm{binary}} = 0.75, versus 0.03 with the dedicated reason. If forced binary adjudication were already as accurate as the dedicated reason, the benefit would collapse to zero.
That is the correct interpretation of falsifiability in this protocol. E3 does not establish that the true accuracy gap is 0.30, or even that a gap of this magnitude exists in practice. It shows the consequence of such a gap if it exists. The empirical size of the gap remains uncertain and should be estimated from live DDR case data or from a dedicated adjudication experiment. The design claim defended here is therefore narrower: forcing non-falsifiable propositions into a binary court can be costly, and the cost grows directly with both prevalence and adjudication difficulty.
9.6 E4: Author reputation after the redesign
The reputation redesign is one of the biggest differences between the current protocol and earlier drafts. Reputation is no longer a generic quantity that directly adds to curation weight. The current design eliminates curator reputation entirely and retains only author reputation as a standing non-monetary bond. (E4c was removed when curator reputation was eliminated; the remaining labels are preserved for cross-reference continuity.)
9.6.1 E4a: author reputation as a standing bond
E4a models honest and dishonest authors under the current author-reputation rules: slow decay, small gains for publication that survives challenge, and large slashes for debunked publication. Unlike the earlier single-trajectory version, the current evaluation averages 100 seeds and varies the dishonest author’s challenge-survival probability as a limited sensitivity check.
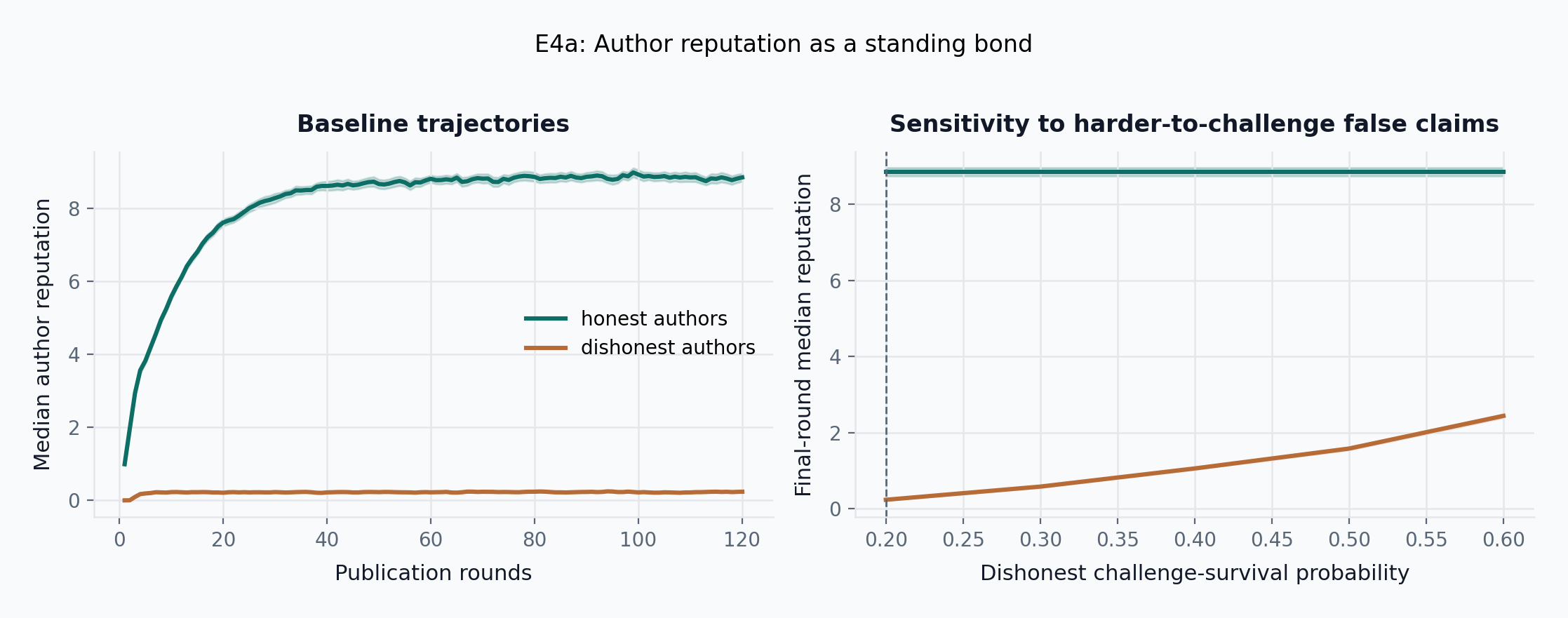
Under the baseline assumptions, the separation is clear but now quantified with uncertainty. By round 120, honest authors accumulate substantial standing reputation while dishonest authors remain near zero because repeated debunking keeps destroying their standing stock. That is the intended role of author reputation in this design: a non-transferable, slowly earned credibility layer that is expensive to squander.
The sensitivity sweep matters because the dishonest author’s challenge-survival probability is the main load-bearing behavioral assumption in this toy model. As that probability rises from 0.20 to 0.60, dishonest reputation rises materially, but the gap from honest authors remains substantial over the tested range. This strengthens the claim that author reputation can separate persistently accurate from persistently inaccurate publishers under a wider range of assumptions than the original single run suggested. It does not eliminate the main limitation: the sweep varies one adversarial parameter while holding publication timing, claim selection, reward size, slash rate, and honest-author success fixed, so it is still not a full model of strategic adaptation.
9.6.2 E4b: counterfactual single-attacker reputation gaming
The current protocol has no curator-reputation path to attack: drafting and voting are purely stake-driven. But the discarded reputation-weighted design is still worth stress-testing, because it clarifies why that design was removed. E4b therefore evaluates a counterfactual legacy committee in which one attacker begins with high inherited reputation (rep_0 = 200) against honest curators sitting near their steady-state reputation. The attacker then votes for 300 rounds under three behaviors: uniform random voting, a small coherent upward bias (+0.15), and a larger coherent upward bias (+0.30). Reputation decays at rate \delta each round, and only votes that remain inside the same K\sigma coherence band used elsewhere in the paper replenish reputation.
The two tracked outcomes are the ones that matter for a reputation-gaming attack. First, how long does the attacker keep above-median committee weight despite no longer reporting honestly? Second, how much directional signal shift does the attacker induce relative to the honest-only committee mean? This is deliberately narrower than E2-Adv: E2-Adv studies coalition manipulation in the current stake-only design, whereas E4b asks whether a single reputation-rich curator would remain dangerous if reputation-weighted curation were reintroduced.
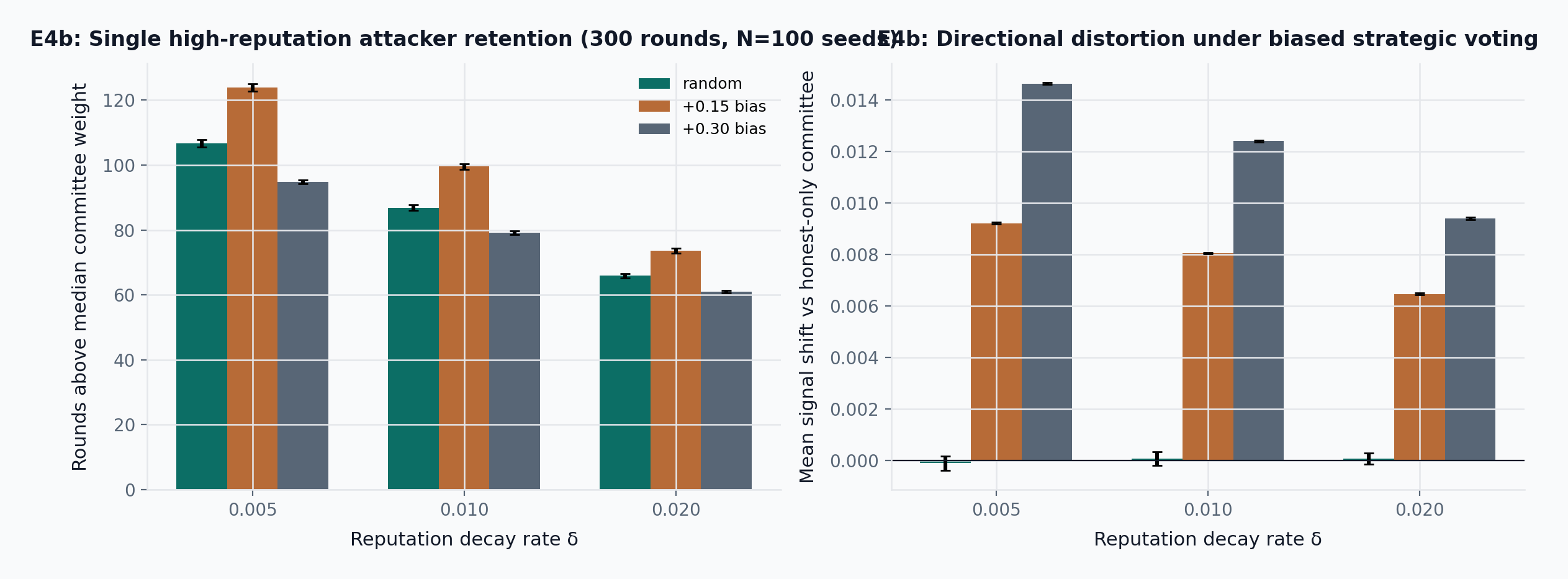
The qualitative result is the one that matters for design. Faster decay reduces attacker persistence across all three variants, so \delta still dominates the long-run cleanup rate. But a small coherent bias is harder to eject than a random attacker because it sometimes remains inside the coherence band and keeps replenishing reputation, while still inducing a persistent directional distortion. A larger bias shifts the signal more aggressively but also becomes easier to detect, so it does not survive as long as the subtler attacker. The right conclusion is not that the current protocol has a hidden E4b vulnerability. It is that the older reputation-weighted path would have created one, and the decision to remove curator reputation from drafting and voting was therefore well-motivated by this class of attack.
9.6.3 E4d: cross-domain reputation scoping
The current design has no reputation-weighted curation, so the relevant cross-domain attack is narrower than in earlier drafts. The question is not whether imported reputation changes voting weight; it is whether reputation earned in an easy or low-stakes pool can be carried into a different pool and appear there as misleading publisher credibility context. E4d therefore models two pools. In Pool L, the attacker behaves honestly for 80 rounds and accumulates author reputation. In Pool H, the attacker then publishes dishonest claims for 40 rounds while locally honest Pool H authors continue publishing. The scoped condition resets the attacker’s Pool H reputation to zero at entry. The unscoped condition imports the Pool L stock unchanged.
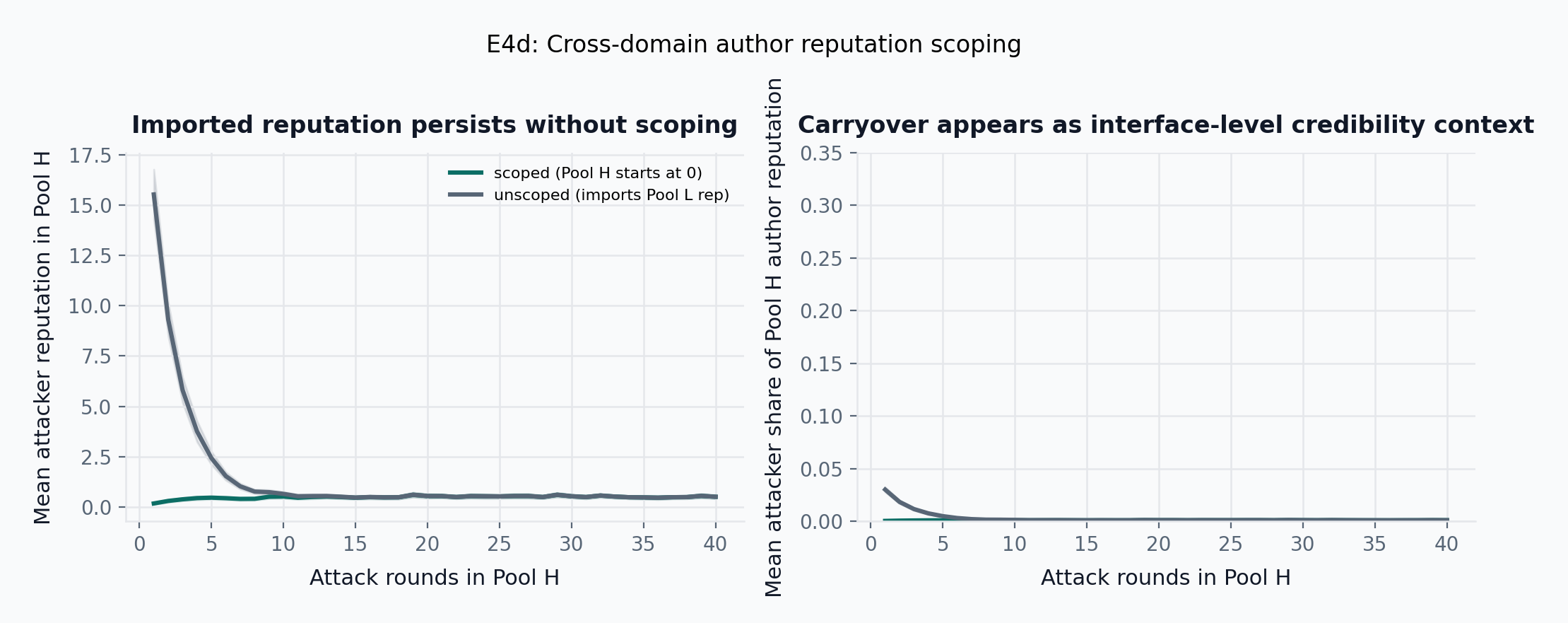
The result is clean. When reputation is pool-scoped, the attacker enters Pool H with no imported credibility and can acquire visibility there only from Pool H outcomes. When transfer is allowed, the attacker arrives with a large stock of borrowed reputation from Pool L, and that stock briefly gives the attacker a meaningful share of the author-reputation context visible in Pool H even while the attacker is behaving dishonestly there. In the representative summary, the first 10 attack rounds show a substantial gap between the unscoped and scoped conditions, but the imported advantage burns off after repeated debunking in roughly ten rounds. That means decay and slashing eventually erase the carryover, but only after a window in which interfaces could display credibility that was earned in the wrong domain. On the current design, pool scoping eliminates author-reputation carryover by construction. Other interface-level credibility signals, such as cross-pool publishing history displayed outside the protocol state, remain outside the protocol’s scope and require interface discipline. The residual risk is local rather than cross-domain: a dishonest author can still accumulate some Pool H reputation if some Pool H claims survive challenge, but that happens in both conditions and is not reputation laundering from another pool.
10 Boundary Conditions And Open Problems
This paper establishes an end-state protocol architecture, a mechanism decomposition by quality dimension, and a simulation-based evaluation program grounded in a partial historical deployment. Its claims are bounded by explicit empirical and operational conditions: the evaluation is design-analytic and simulation-based, not a report from live deployment at scale.
10.1 Empirical boundary
No live deployment validates the complete design. Truth Post validated a partial predecessor. The claims about incentive alignment, competence filtering, and falsifiability defense are claims about the specified design under the analyzed assumptions, not about field performance at scale.
10.2 Inherited dependencies
The protocol delegates accuracy adjudication to an external DDR layer. That is a deliberate modular choice: the design reuses an existing court rather than solving decentralized dispute resolution from first principles inside the protocol itself. The tradeoff is direct. If the external court is captured, lazy, or inaccurate, the accuracy layer inherits that degradation.
This paper does not model the token-market cost of capturing the external court or the economics of forking away from a captured court. Any claim that external DDR capture is uneconomic depends on provider-specific market capitalization, circulating float, liquidity, and attacker budget, and is therefore outside the paper’s validated claims.
The relevance layer has a parallel boundary. Drafting uncertainty, draw-and-lock staking, graduated slashing, and relevance-round escalation make collusive distortion harder and costlier, but they do not eliminate it. Sufficiently large coordinated blocs can still bend relevance signals.
10.3 Pool quality, interface burden, and cold start
Permissionless pool creation is the right architectural stance because it keeps bad policy local rather than protocol-global. The curation policy functions as the law of a pool: the pool creator defines what “relevant” means, and the coherence game turns curators into enforcers of that definition through slashing and rewards. If the policy is bad, curation will be bad, but that is a policy-level problem, not a protocol flaw, just as a bad law is not a failure of the concept of law enforcement.
The defense against bad policy is competitive selection, not governance. The dynamic is the same as newspapers and online communities: creating a newspaper is permissionless, but if you publish poorly, no one reads it and it falls into irrelevance. Multiple subreddits can exist on the same topic; users gravitate to the best-curated one and the rest are outselected naturally. People vote with their feet. The protocol does not need to prevent bad pools; it needs to make pool creation cheap and switching costs low enough that competitive selection can function. The blueprint identifies residual switching frictions (reputation lock-in, funder coordination, round-cycle capital commitment) that may slow this dynamic in practice. Interfaces still need to decide which pools to feature, warn about, or ignore, and cross-pool aggregation remains an interface concern by design rather than a protocol responsibility.
The same locality applies to policy quality and bootstrap. The coherence game works only when a pool’s relevance policy is specific enough to discipline scoring, and new pools still need readers, challengers, curators, and budget. The current design makes these requirements explicit instead of hiding them behind protocol-wide governance, but it does not remove them.
Canonical protocol state is public and on-chain. Third-party aggregators can read verified curation outputs without participating in or funding the protocol. This is a feature, not a bug: the design goal is trustless knowledge production, and restricting read access would contradict that goal. The tradeoff is that pool funding depends entirely on exogenous sponsors and creators, since no protocol mechanism captures value from downstream consumers of the curated signal.
10.4 Operational deployment constraints
Immutable contracts avoid one class of governance risk, but they require explicit migration discipline. New versions must coexist with old ones, and interfaces must aggregate across versions when continuity matters.
Scalability, structured claim authoring, challenge participation, legal exposure, and interface discoverability are practical deployment constraints. Pooled staking and random drafting do not establish immunity from targeted legal action. They do not undercut the conceptual framework, but they do determine whether a specified protocol becomes a robust live system.
11 Conclusion
The working hypothesis of this paper is that the bottleneck behind many information-heavy coordination problems is not governance, voting, or coordination in the narrow sense, but the upstream transformation of raw information into decision-grade knowledge. I call that transformation curation. The paper examines this hypothesis on one domain (news) and sketches its application to a second (advertising); whether the decomposition holds more broadly remains an open question.
The paper contributes a general framework for trustless decentralized curation and instantiates it for news. The framework starts with problem definition, identifies the relevant quality dimensions, requires falsifiability where challenge is the mechanism, and designs incentives dimension by dimension rather than collapsing everything into one score. In the news instantiation, that yields an accuracy layer based on bonded publication and open challenge, and a relevance layer based on drafted curator rounds under a public policy.
The current Truth Post design reflects a clear architectural stance: permissionless pools, immutable contracts, minimal governance, explicit protocol-interface separation, local pool economics, confidence as bond-time rather than truth label, author reputation as a standing non-monetary bond, typed challenge reasons (NonFalsifiable, ScopeViolation, TemplateViolation), bond adjustment with grace period, flat evidence items aligned with the external DDR, and challenge pinning to the exact revision and bond at filing time.
The evaluation results are informative and bounded. Debunking false claims can be economically rational. Drafted-curator relevance rounds filter competence while remaining vulnerable above a concrete collusion threshold. The E3 scenario analysis shows that dedicated NonFalsifiable challenges can materially reduce bad-item retention if they produce a real adjudication-accuracy advantage over forced binary treatment. Author reputation as a standing bond creates useful separation under the tested range without reintroducing reputation-weighted voting, and pool scoping prevents cross-pool author-reputation carryover by construction.
Truth Post 2023 matters because it moved this work beyond pure speculation. The complete system is not yet deployed, but the end-state design is now specified, stress-tested, and conceptually cleaner than the MVP that preceded it.
What this paper ultimately claims is not that one protocol solves all epistemic problems. It claims that trustless decentralized curation is a real field, that its main bottleneck has been identified clearly, that the framework for attacking it is now explicit, and that the path from theory to buildable system is much shorter than it appears from the outside.
12 Disclosure
The author has multi-year engineering experience with Kleros, a deployed decentralized dispute resolution system. That experience informs the design choices and threat model but does not constitute empirical validation. No deployment data from Kleros is used in this paper. The author does not hold PNK tokens and has no ongoing financial relationship with Kleros.